Mehmet İşcan
Arkadaşlar merhaba.
Yıldız Teknik Üniversitesi Mekatronik Mühendisliği bölümünde doktor ogretim uyesi olarak çalışmaktayım. Mekatronik mühendisliğinden mezun olduktan sonra çeşitli dersler için videolar hazırlamaktayım.
Biyomedikal alanında yüksek lisans tezimi tamamlayıp, şu anda doktora çalışmaları gerceklestirdim. Ayrıca özel sektörde çeşitli projeler geliştirmekte ve ülkemizdeki bilimsel anlayışı felsefe tabanında geliştirmeye çalışmaktayım.
Temel alan olarak fizyolojik modelleme, yapay zeka, sinyal işleme ve kontrol teorisi üzerine bilimsel araştırmalarımı yürütmekteyim.
Ayrıca ülkemizdeki bilimsel projelerin arge süreçlerinden çıkarılıp topluma kazandırılması için yazılım-elektronik-makina etkileşimli cihazlar tasarlamaktayım.
Umarım derslerim sizin için aydınlatıcı olur :)
Beni desteklemek isterseniz,
https://www.patreon.com/mehmet_iscan
https://medium.com/@mehmetiscan
https://www.researchgate.net/profile/Mehmet_Iscan2

Reinforcement Learning - Les 14-15 - Off Policy Approximation - Optimal Control and RL Examples

Reinforcement Learning - Les 14-14 - Off Policy Approximation - Traces with Control Variates

Reinforcement Learning - Les 14-13 - Off Policy Approximation - Variable Lambda and Gamma

Reinforcement Learning - Les 14-12 - Off Policy Approximation - SARSA Lambda Learning

Reinforcement Learning - Les 14-11 - Off Policy Approximation - Dutch Traces in Monte Carlo
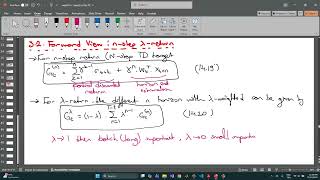
Reinforcement Learning - Les 14-10 - Off Policy Approximation - True Online TD Lambda Method

Reinforcement Learning - Les 14-8 - Off Policy Approximation - Forward View Online Update

Reinforcement Learning - Les 14-9 - Off Policy Approximation - Optimal Control Example

Reinforcement Learning - Les 14-7 - Off Policy Approximation - Recursive TD and Lambda Return

Reinforcement Learning - Les 14-6 - Off Policy Approximation - N-Step Truncated Lambda Return

Reinforcement Learning - Les 14-5 - Off Policy Approximation - Eligibility Traces Optimal Control

Reinforcement Learning - Les 14-4 - Off Policy Approximation - Semi Gradient TD Lambda Estimation

Reinforcement Learning - Les 14-3 - Off Policy Approximation - TD Lambda and Operators

Reinforcement Learning - Les 13-15 - Off Policy Approximation - GTD2 and TDC Algorithm

Reinforcement Learning - Les 14-2 - Off Policy Approximation - Lambda N-Step Return and Operator

Reinforcement Learning - Les 13-17 - Off Policy Approximation - Emphatic TD Methods

Reinforcement Learning - Les 14-1 - Off Policy Approximation - Eligibility Traces

Reinforcement Learning - Les 13-16 - Off Policy Approximation - RL and Optimal Control Example

Reinforcement Learning - Les 13-14 - Off Policy Approximation - Gradient TD Methods

Reinforcement Learning - Les 13-11 - Off Policy Approximation - True Gradient and Hessian

Reinforcement Learning - Les 13-13 - Off Policy Approximation - HJB Residuals and Difficulties

Reinforcement Learning - Les 13-12 - Off Policy Approximation - Divergence and Deadly Triad

Reinforcement Learning - Les 13-8 - Off Policy Approximation - TD(0) Fixed Point Equation

Reinforcement Learning - Les 13-10 - Off Policy Approximation - Gradient Descent for Bellman Error

Reinforcement Learning - Les 13-7 - Off Policy Approximation - Linear Value - Function Geometry

Reinforcement Learning - Les 13-9 - Off Policy Approximation - HJB and Optimal Control

Reinforcement Learning - Les 13-6 - Off Policy Approximation - Off Policy Divergence

Reinforcement Learning - Les 13-5 - Off Policy Approximation - DC Motor Control in Policies

Reinforcement Learning - Les 13-4 - Off Policy Approximation - Semi-Gradient TD(0) Update

Reinforcement Learning - Les 13-3 - Off Policy Approximation - On-Policy TD(0) in Bellman