Language Model Alignment: Theory & Algorithms
Автор: Simons Institute for the Theory of Computing
Загружено: 2024-09-12
Просмотров: 822
Ahmad Beirami (Google)
https://simons.berkeley.edu/talks/ahm...
Emerging Generalization Settings
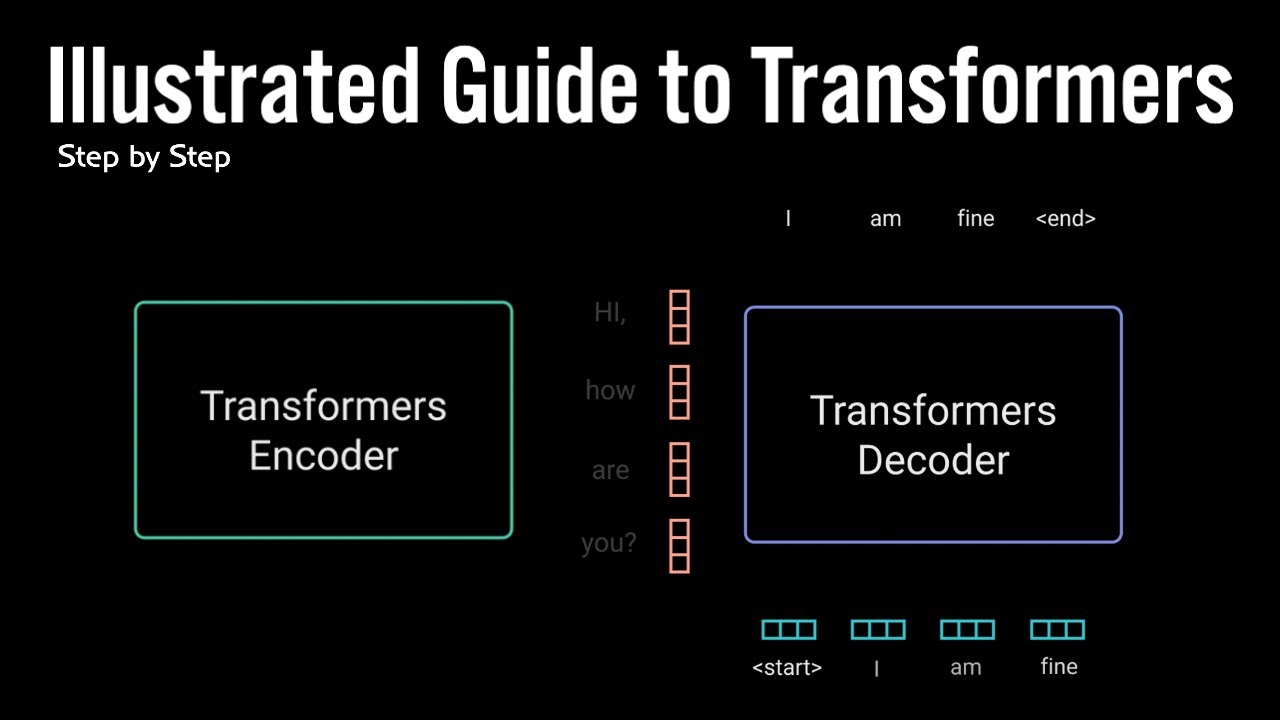
The goal of the language model alignment (post-training) process is to draw samples from an aligned distribution that improves a reward (e.g., make the generation safer or more factual) but does not perturb much from the base model. A simple baseline for this task is best-of-N, where N responses are drawn from the base model, ranked based on a reward, and the highest ranking one is selected. More sophisticated techniques generally solve a KL-regularized reinforcement learning (RL) problem with the goal of maximizing expected reward subject to a KL divergence constraint between the aligned model and the base model. In this talk, we give an overview of language model alignment and give an understanding of key results in this space through simplified examples. We also present a new modular alignment technique, called controlled decoding, which solves the KL-regularized RL problem while keeping the base model frozen through learning a prefix scorer, offering inference-time configurability. Finally, we also shed light on the remarkable performance of best-of-N in terms of achieving competitive or even better reward-KL tradeoffs when compared to state-of-the-art alignment baselines.

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



![Неожиданная правда о 4 миллиардах лет эволюции [Veritasium]](https://imager.clipsaver.ru/Unxh6MnVIWc/max.jpg)