Transformer Deep Dive 🤖⚙️ (Based on “Attention Is All You Need”)
Автор: Dream it Learn it
Загружено: 2025-12-26
Просмотров: 13
🤖✨ Transformer finally makes sense — in this video I explain the Transformer architecture step by step, based on the original paper “Attention Is All You Need.” No fluff, just a clear big picture and the core mechanics.
📌 What you’ll learn in this video
• Where Transformer sits in AI and why it became a foundation architecture 🌍
• The motivation: why RNNs & CNNs struggled (sequential ops + long-range dependencies) 🚧
• The high-level encoder–decoder structure 🏗️
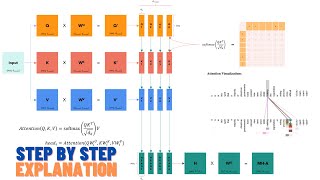
• Scaled dot-product attention (Q, K, V) explained clearly 🔎
• Multi-head attention: why multiple heads matter 👀👀
• The 3 ways attention is used: encoder self-attention, decoder masked self-attention, cross-attention 🔁
• Position-wise feed-forward networks (FFN) ⚙️
• Positional encoding: why we need it, and why sine/cosine helps 📍🌊
• Embeddings + weight sharing for efficiency 🧩
• Final recap: why Transformer won 🏁

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: