How Ceph Writes Data: Complete Journey from Client to OSD
Автор: EC INTELLIGENCE
Загружено: 2025-10-12
Просмотров: 125
🔄 Ever wonder how Ceph achieves linear scalability? The secret is in the data flow! Learn how Ceph eliminates metadata bottlenecks that plague traditional storage systems.
📚 MASTER CEPH (25 HANDS-ON LABS):
👉 https://www.udemy.com/course/ceph-sto...
⏱️ TIMESTAMPS:
0:00 - Why Ceph's Data Flow is Revolutionary
0:45 - Traditional Storage Problems (Metadata Bottleneck)
1:30 - Step 1: Client Authentication with CephX
2:15 - Step 2: Cluster Maps Distribution
3:00 - Step 3: Object Creation & PG Calculation
3:45 - Step 4: Direct Write to Primary OSD
4:30 - Step 5: Replication & Acknowledgment
5:30 - Live Demo: Watch it Happen
7:00 - Traditional vs Ceph Comparison
8:15 - Why This Matters for Performance
9:00 - Key Takeaways
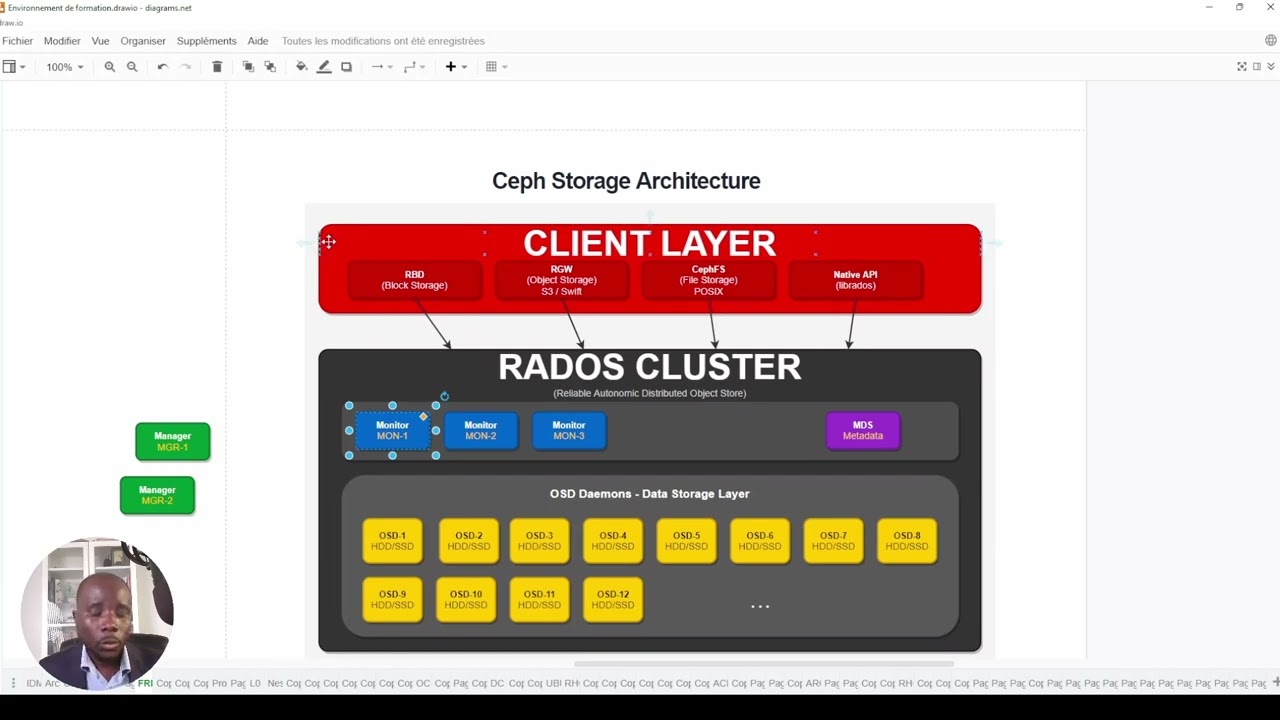
🎯 THE COMPLETE WRITE JOURNEY (5 STEPS):
STEP 1: CLIENT AUTHENTICATION
→ Client reads ceph.conf to locate Monitors
→ Presents keyring for CephX authentication
→ Monitor validates credentials
→ Secure access granted
STEP 2: RECEIVE CLUSTER MAPS
→ Monitor sends latest cluster maps
→ OSD map (which OSDs are up/down)
→ CRUSH map (data placement rules)
→ PG map (placement group states)
→ Current epoch for consistency
STEP 3: OBJECT CREATION & PG CALCULATION
→ Client splits data into 4MB objects (default)
→ Hashes object name to determine PG
→ Uses CRUSH algorithm locally to map PG → OSDs
→ NO metadata server lookup needed!
*STEP 4: WRITE TO PRIMARY OSD* 💾
→ Client writes directly to primary OSD
→ Primary OSD simultaneously:
• Writes to local disk (BlueStore)
• Replicates to secondary OSDs
→ Parallel writes for performance
STEP 5: ACKNOWLEDGMENT
→ Secondary OSDs confirm write
→ Primary OSD confirms write
→ Only after ALL replicas written
→ Primary sends ACK to client
→ Write is now durable and consistent
🚀 WHY THIS IS REVOLUTIONARY:
Traditional Storage:
❌ Metadata server lookup required
❌ Single point of bottleneck
❌ Serial operations (lookup → write → replicate)
❌ Metadata server scales poorly
Ceph Storage:
✅ Client calculates everything locally
✅ No metadata bottleneck
✅ Parallel writes to all replicas
✅ Linear scalability
✅ Direct OSD communication
💡 KEY ADVANTAGES EXPLAINED:
No Metadata Server Lookup
→ Traditional: Client asks "where should I write?" (bottleneck)
→ Ceph: Client calculates using CRUSH (instant)
Deterministic Placement
→ Same input → same result every time
→ Any client can calculate any object's location
→ No central lookup table to maintain
Strong Consistency
→ ACK only after all replicas written
→ No "eventual consistency" trade-offs
→ Data is durable when write completes
Linear Performance Scaling
→ More OSDs = more parallel I/O paths
→ No controller head bottleneck
→ Each OSD processes independently
📊 REAL-WORLD IMPACT:
Performance:
→ 10,000 IOPS per OSD typical
→ 100-node cluster = 1,000,000+ IOPS
→ No single component limits scaling
Reliability:
→ Self-healing: automatic recovery
→ Self-managing: no manual intervention
→ Configurable replication (size=3 default)
Flexibility:
→ Same cluster serves block, object, file
→ Unified storage for all workloads
🔍 DEEP DIVE TOPICS (Covered in Full Course):
CRUSH Algorithm Details:
→ Pseudo-random placement
→ Failure domain awareness
→ Weight-based distribution
→ Rule customization
Placement Groups (PGs):
→ Abstraction layer benefits
→ PG calculation formula
→ Optimal PG counts
→ PG states explained
Replication Strategies:
→ 3x replication default
→ Erasure coding alternative
→ min_size considerations
→ Durability calculations
BlueStore Backend:
→ Direct block device management
→ RocksDB for metadata
→ Write-ahead log (WAL)
→ Compression & checksums
📚 COMPLETE CEPH MASTERY COURSE:
Get hands-on experience with 25 production labs:
✅ Deploy complete clusters
✅ Configure CRUSH maps
✅ Manage pools & PGs
✅ Monitor & troubleshoot
✅ Operations & recovery
✅ Security best practices
👉 https://www.udemy.com/course/ceph-sto...
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



















