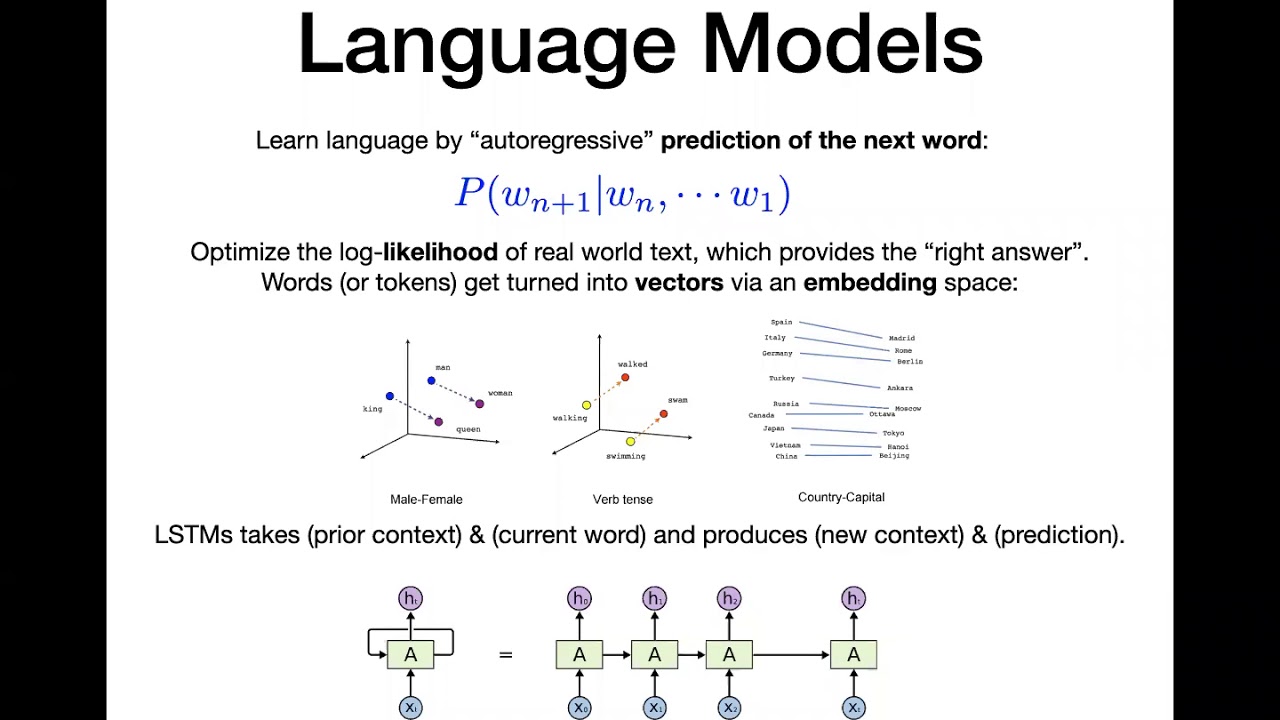
Neural network architectures, scaling laws and transformers
Автор: Samuel Albanie
Загружено: 2022-04-27
Просмотров: 2731
A summary of research related to Neural Network Architecture design, Scaling Laws and Transformers.
Detailed description:
We first look at different strategies for neural network design: human design, random wiring, evolutionary algorithms and neural architecture search. As an example of neural architecture search, we explore the DARTS algorithm in some detail.
We then explore scaling phenomena and the role of hardware in modern machine learning. In particular, we look at the economic, hardware and algorithmic factors enabling scaling. We consider the implications of scaling and why this trend may be important.
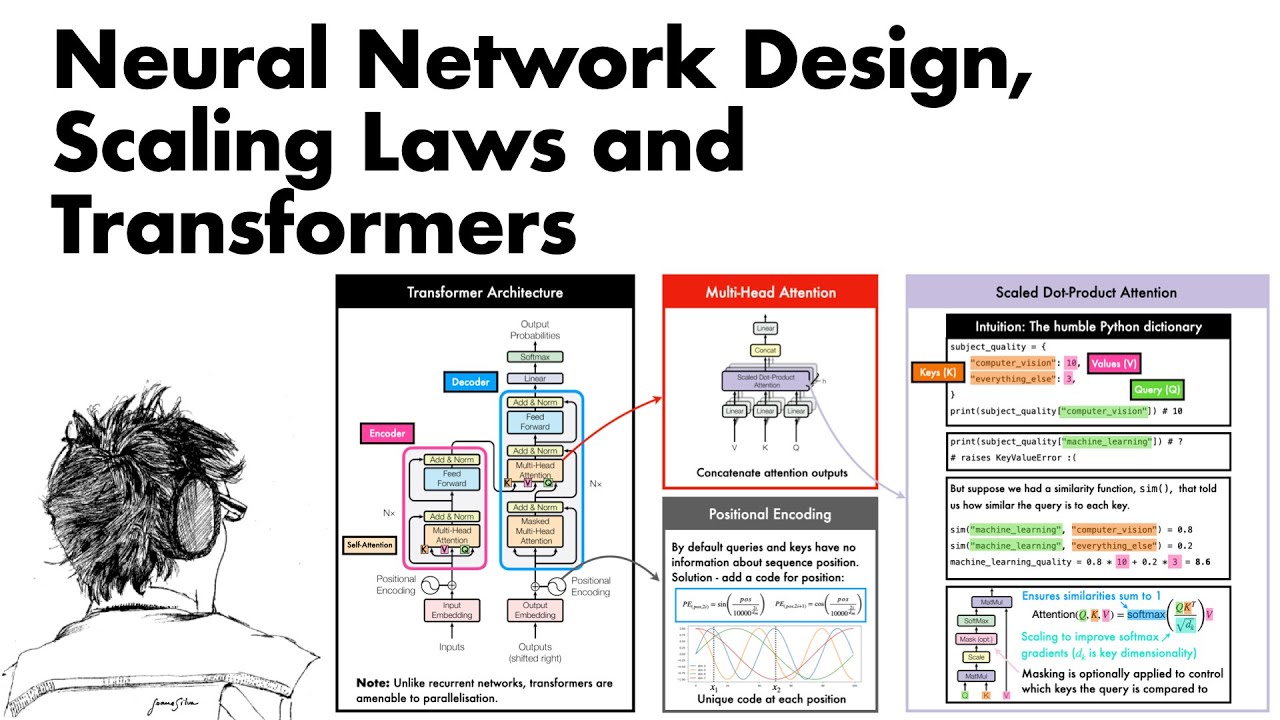
Next, we look at the Transformer, a model that scales effectively with additional compute. We discuss the mechanics of how self-attention works and the encoder-decoder architecture that underpins the transformer.
We then describe transformer scaling laws for natural language, the application of the transformer architecture to vision applications, and the proliferation of transformer variants that have emerged in different domains.
Finally, we briefly discuss the relationship between neural network design and energy consumption, together with some estimates that have been made on the carbon emissions associated with model training.
Timestamps:
00:00 - Neural network architectures, scaling laws and transformers
00:22 - Outline
00:40 - Strategies for Neural Network Design
02:17 - Strategy 1: Neural Network Design by Hand
05:01 - Strategy 2: Random Wiring
08:01 - Strategy 3: Evolutionary Algorithms
10:55 - Strategy 4: Neural Architecture Search
12:11 - DARTS: Differentiable Architecture Search
16:04 - Scaling phenomena and the role of hardware
17:24 - What factors are enabling effective compute scaling?
18:34 - Scaling phenomena and the role of hardware (cont.)
20:28 - The Transformer: a model that scales particularly well
27:05 - Transformer scaling laws for natural language
28:41 - Vision Transformer
31:32 - Transformer Explosion
33:47 - Neural Network Design and Energy Consumption
Topics: #scalinglaws #transformers #neuralnetworks #machinelearning #computervision
Slides: https://samuelalbanie.com/files/diges...
Notes: The content is part of a set of lectures I gave as part of the 2021 4F12 Computer Vision course for undergraduate engineering at the University of Cambridge.
References: A full list of the references for the video can be found at https://samuelalbanie.com/digests/202...
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: