Review DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation ~ Seed-TTS
Автор: Olewave
Загружено: 2025-04-18
Просмотров: 476
This work is done by the group of researchers who built Seed-TTS. To see the review of Seed-TTS:
• Review ByteDance/Tiktok's Seed-TTS: A Fami...
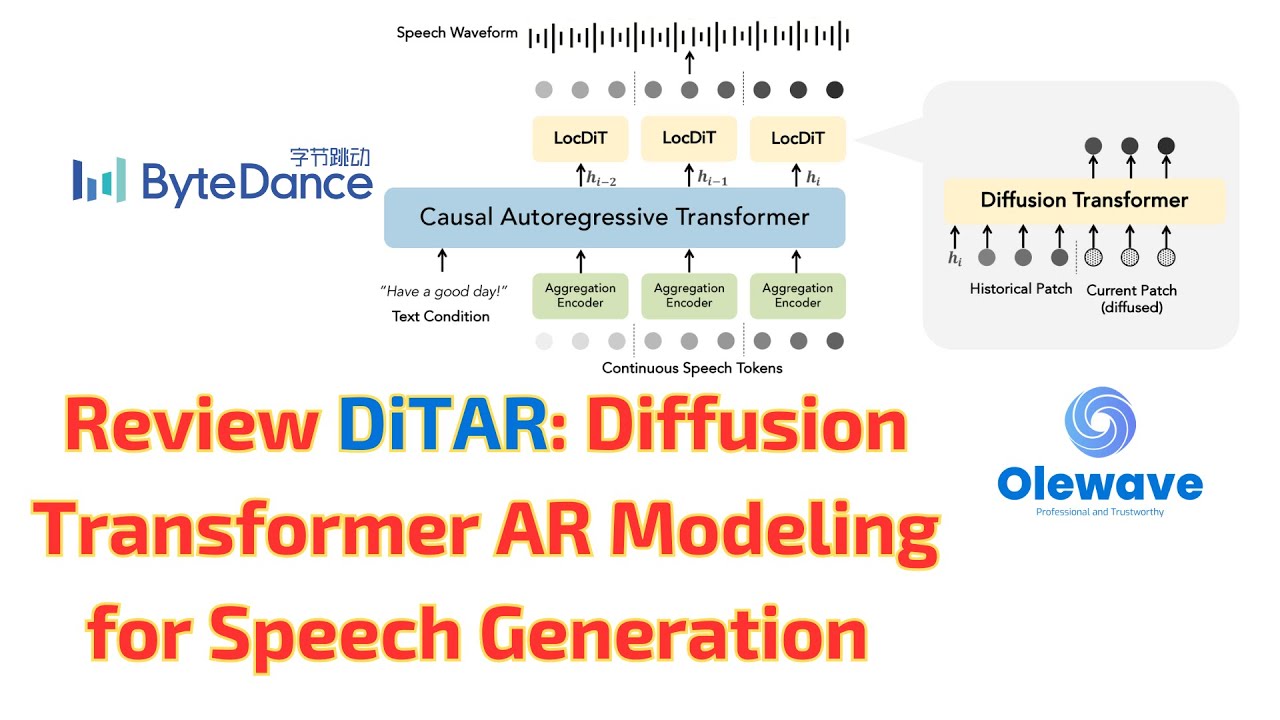
Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes. In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer. This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the language model processes aggregated patch embeddings and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism. We also show in the extensive scaling analysis that DiTAR has superb scalability. In zero-shot speech generation, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness.
#DiTAR #diffusionmodels #diffusion #transformers #seedtts #seed-tts #tts #zeroshottts #zeroshoticl #voiceclone #voiceconversion #deepfake #bytedance #tiktok #genai #speechgenai #cmos
Eager to train your own #Whisper or #GPT-4o model but running out of data? We are proud to offer this unique large-scale conversational speech dataset in different languages and topics for #ASR, #TTS, #NLP, and other conversational AI R&D. It has speaker labels and high quality transcriptions. The duration of the dataset depends on the customer's needs and can extend up to 1 million hours. See the description and samples in the following post:
/ olewave-large-scaled-convesational-speech-...
send an email to info@olewave.com for more details.
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



![[Detailed Paper Reading] Zipformer: A faster and better encoder for automatic speech recognition](https://image.4k-video.ru/id-video/jvtTs9q1l8w)



![[ISAMS 2023] R2_5Korean Medicine Research_2연자 Manseok Kim](https://image.4k-video.ru/id-video/R-CZTsDsAUE)











