Скачать
Transformer Model (2/2): Build a Deep Neural Network (1.25x speed recommended)
Автор: Shusen Wang
Загружено: 2021-04-16
Просмотров: 14819
Описание:
Next Video: • BERT for pretraining Transformers
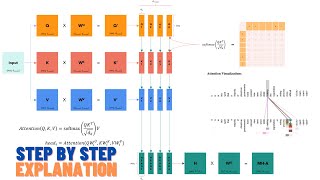
The Transformer models are state-of-the-art language models. They are based on attention and dense layer without RNN. In the previous lecture, we have built the attention layer and self-attention layer. In this lecture, we first build multi-head attention layers and then use them to build a deep neural network known as Transformer. Transformer is a Seq2Seq model that can be used for machine translation.
Slides: https://github.com/wangshusen/DeepLea...
Reference:
Vaswani et al. Attention Is All You Need. In NIPS, 2017.

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:






![Цепи Маркова — математика предсказаний [Veritasium]](https://ricktube.ru/thumbnail/QI7oUwNrQ34/mqdefault.jpg)










![Момент, когда мы перестали понимать ИИ [AlexNet]](https://ricktube.ru/thumbnail/UZDiGooFs54/mqdefault.jpg)
