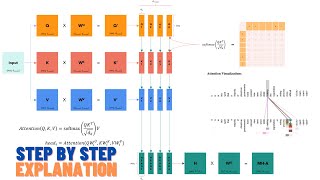
Simplest Explanation of Transformer Architecture: MHA, Positional Encoding, Layer Norm (Add & Norm)
Автор: Sahi PadhAI
Загружено: 2025-10-30
Просмотров: 30
The Complete Transformer Explained: Multi-Head Attention, Positional Encoding, and Layer Normalization. Dive deep into the revolutionary Transformer architecture introduced in the paper "Attention Is All You Need"
This video provides the simplest, most comprehensive explanation of every layer, matrix multiplication, and key component—from Multi-Head Self-Attention (MHA) to Positional Encoding and the critical Add & Norm (Layer Normalization) layer. We'll show you exactly why Transformers stabilize training and accelerate performance, covering the core concepts needed for both academic understanding and technical interviews.
Key Technical Takeaways Covered:Layer Normalization (Layer Norm): We explain why this technique, which normalizes across the features of a single sample , is critical for stabilizing and accelerating Transformer training, especially given the variable sequence lengths and challenges with Batch Norm .The Add & Norm Layer: This combines a Residual Connection (the "Add" part, which minimizes vanishing gradients with Layer Normalization (the "Norm" part) for consistent activation distributions.
References: Attention Is All You Need (Transformer): https://arxiv.org/abs/1706.03762 $$6
Layer Normalization (Original Paper): https://arxiv.org/pdf/1607.06450.pdf
Layer Normalization in Transformer Architecture: https://arxiv.org/pdf/2002.04745.pdf
#Transformer #LayerNormalization #SelfAttention #NLP #MachineLearning #DeepLearning #AIExplained
Timestamp
==============================================================
00:00 - Introduction to Sequence Models and the Need for Attention
02:24 - The Bottleneck: Why Self-Attention Was Essential for Transformers
03:39 - Transformer Architecture: High-Level Overview (Encoder-Decoder)
04:52 - Multi-Head Self-Attention (MHA) Explained: The Core Mechanism
12:09 - Encoder Block Breakdown: Add & Normalize Layer and Scaling (sqrt(d_k))
18:46 - Positional Encodings: Injecting Order into the Transformer
22:06 - Self-Attention as a Matrix Operation: Parallel Calculation Explained
24:57 - Parameter Counting: How to Calculate Total Parameters in the Encoder
27:54 - Top Interview Questions on Transformer Architectures (Google/FAANG)
==============================================================
NLP Playlist: • Natural Language Processing in HIndi Full ...
AI Podcast: • AI Podcast
Fundamentals of AI: • Your Complete AI Roadmap | LLM full course...
🎓 Learn Advanced NLP & AI — from RNNs to Agentic AI.
This channel dives deep into the architectures powering today’s intelligent systems — Attention Networks, Transformers, RAG, and beyond.
You’ll gain interview-ready understanding, hands-on coding insights, and clarity to build and explain AI systems like a pro.
Perfect for learners aiming for MAANG roles or AI specialization.
🚀 Let’s decode AI — one neural network at a time.
#NLP #AI #MachineLearning #DeepLearning #Transformers #AgenticAI #MAANGPrep
Gain knowledge, spread knowledge, and make the world a better place.
We will do sahi padhai together #sahipadhai.
#nlp #naturallanguageprocessing #algorithm #nlplectureinhindi

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: