Скачать
Transformer Encoder Explained with Visuals | Attention, Embedding, PE, Residual Connections
Автор: Build AI with Sandeep
Загружено: 2025-11-18
Просмотров: 8
Описание:
Welcome to Build AI with Sandeep!
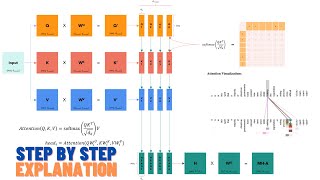
In this video, we will understand the complete Transformer Encoder architecture in a very simple and visual way — no complex math, no confusion.
🔹 What you will learn in this video:
✔ Word Embedding & Tokenization
✔ Positional Encoding (Why and How?)
✔ Scaled Dot-Product Attention (Simple explanation)
✔ Multi-Head Self Attention
✔ Add & Norm (Residual Connections + LayerNorm)
✔ Feed Forward Neural Network
✔ Final Encoder Output (Contextual Embedding)

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: