How to train LLMs with long context?
Автор: Deep Learning with Yacine
Загружено: 2025-05-09
Просмотров: 4819
In today's video, I wanted to cover context windows in the transformer's architecture and how to make them BIG.
Table of Content
Introduction: 0:00
Why more context is good: 0:33
R1 longer context: 1:06
A little retrieval test: 1:56
Needle-in-a-haystack: 2:40
Multi-Round Needle-in-a-haystack: 3:38
Machine Translation from One Book MTOB: 4:52
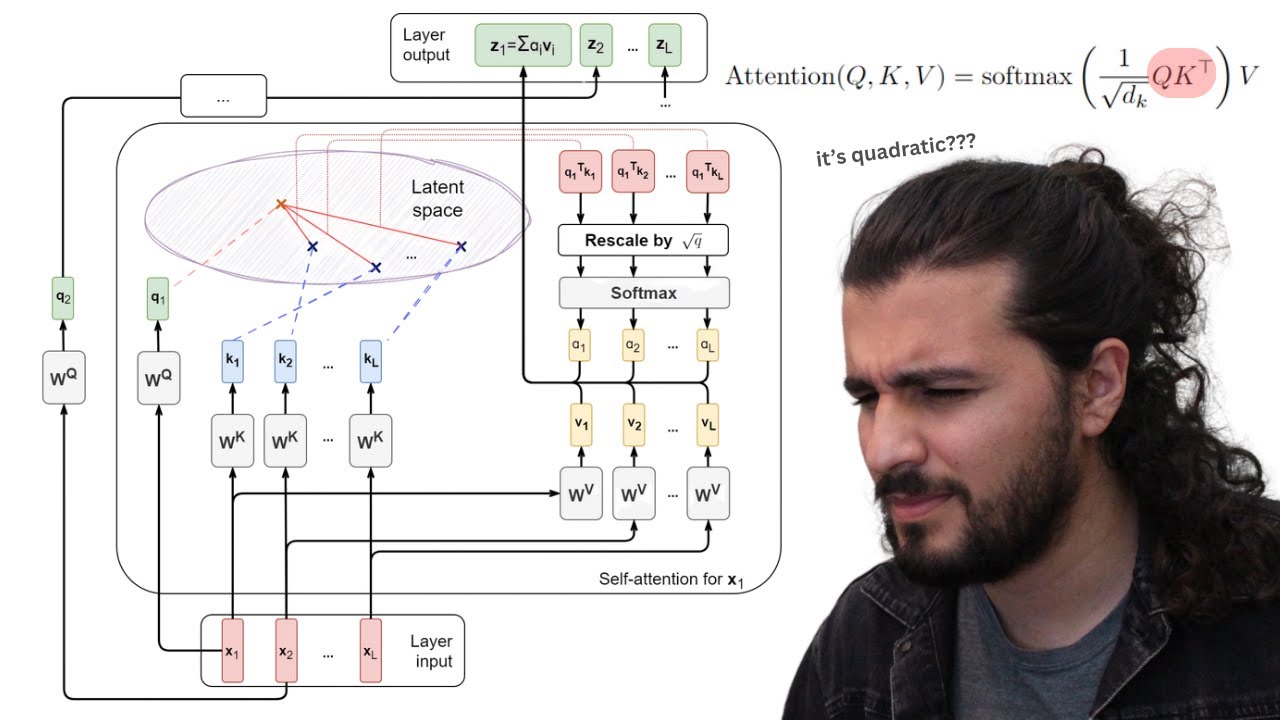
Attention Calculation Recap: 6:16
How to encode positions: 8:51
Issue with increasing context: 10:07
How to extend context: 11:26
Fixing positional encoding: 11:45
Fixing Attention Calculation: 13:21
Flash Attention: 13:55
Sparse Attention: 14:52
Low-Rank Decomposition: 18:14
Chunking: 19:51
Other type of strategy using linear components: 21:44
LLama 4 changes: 24:12
Google Long Context Team (Nikolay Savinov): 25:33
see you folks! : 26:50
This is an especially interesting topic, at least for me, to dig into because we are starting to see models with quite large context windows.
For example, Gemini 2.5 has a context window of 1M tokens and Llama4 scout boasts 10M.
Here are all the resources in this tutorial:
📌 LLama 4 report on their 10M context window: https://ai.meta.com/blog/llama-4-mult...
📌 Gemini 2.5 release note: https://blog.google/technology/google...
📌 Very solid review of transformers: https://synthesis.ai/2023/12/04/gener...
📌 And another very solid review of long context: https://synthesis.ai/2024/04/08/lost-...
📌 How Rotary Position Embedding Supercharges Modern LLMs: • How Rotary Position Embedding Supercharges...
📌 On The Computational Complexity of Self-Attention: https://arxiv.org/abs/2209.04881
📌 Extending Context Window of Large Language Models via Positional Interpolation: https://arxiv.org/abs/2306.15595
📌 Long-Context LLM Extension with Positional Encoding: • Long-Context LLM Extension
📌 A Controlled Study on Long Context Extension and Generalization in LLMs: https://arxiv.org/abs/2409.12181
📌 Flash Attention: https://arxiv.org/abs/2205.14135
📌 Generating Long Sequences with Sparse Transformers: https://arxiv.org/pdf/1904.10509
📌 Big Bird: Transformers for Longer Sequences: https://arxiv.org/abs/2007.14062
📌 The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs: https://arxiv.org/abs/2504.17768
📌 Linformer: Self-Attention with Linear Complexity: https://arxiv.org/abs/2006.04768
📌 Rethinking Attention with Performers: https://arxiv.org/abs/2009.14794
📌 Transformer Quality in Linear Time: https://arxiv.org/abs/2202.10447
📌 Various Lengths, Constant Speed: Efficient Language Modeling with Lightning
Attention: https://arxiv.org/pdf/2405.17381
📌 MiniMax-01: Scaling Foundation Models with Lightning Attention: https://arxiv.org/abs/2501.08313
📌 MEGABYTE: Modeling Million-byte Sequences with
Multiscale Transformers: https://proceedings.neurips.cc/paper_...
📌 Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention: https://arxiv.org/abs/2404.07143
📌 Titans: Learning to Memorize at Test Time: https://arxiv.org/abs/2501.00663
📌 Efficiently Modeling Long Sequences with Structured State Spaces: https://arxiv.org/abs/2111.00396
📌 Linear Attention and Mamba: New Power to Old Ideas: https://synthesis.ai/2024/11/20/linea...
📌 Command A: An Enterprise-Ready Large Language Model: https://cohere.com/research/papers/co...
📌 Scalable-Softmax Is Superior for Attention: https://arxiv.org/pdf/2501.19399
----
Join the newsletter for weekly AI content: https://yacinemahdid.com
Join the Discord for general discussion: / discord
----
Follow Me Online Here:
Twitter: / yacinelearning
LinkedIn: / yacinemahdid
___
Have a great week! 👋
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:











![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)






![How AI Taught Itself to See [DINOv3]](https://imager.clipsaver.ru/oGTasd3cliM/max.jpg)
