Скачать
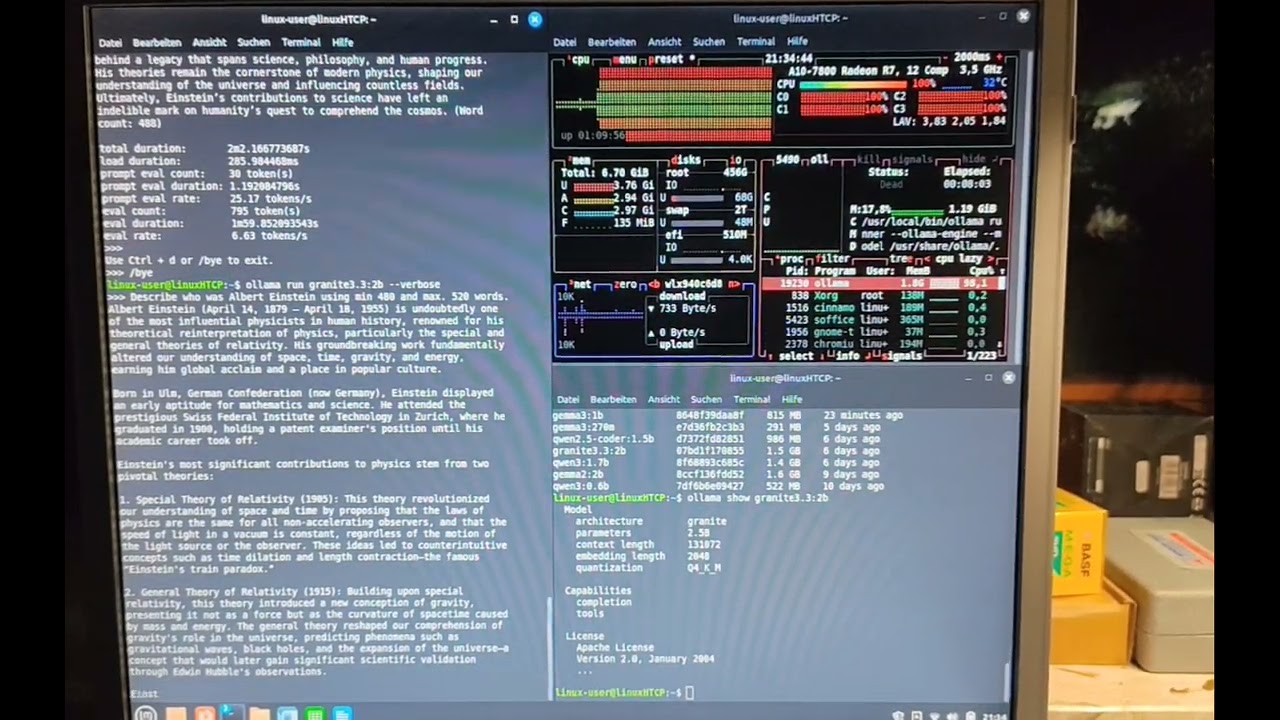
Performance of small LLM (IBM granite3.3 with 2.5B parameter) using ollama on an AMD A10 7800 CPU.
Автор: Ralf Trosien
Загружено: 2026-01-22
Просмотров: 4
Описание:
In this video, you can watch my old HTPC—built around an AMD A10-7800 APU for socket FM2+ from around 2014 and equipped with 8 GB of DDR3 RAM—try to explain who Albert Einstein was in just 500 words. For this test, I used Ollama running IBM’s Granite 3.3 small language model with 2.5 billion parameters. The text gets produced with a speed of 3.1 token/s which is just borderline fast. Even a small halucnization can be witnessed :-)
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



















