RAG-System mit PDFs, Tabellen & Bildern (n8n KI Chatbot)
Автор: Philip Thomas
Загружено: 2026-01-16
Просмотров: 438
PRO-Community: https://philipthomas.de/pro
Supabase Langchain Doku: https://supabase.com/docs/guides/ai/l...
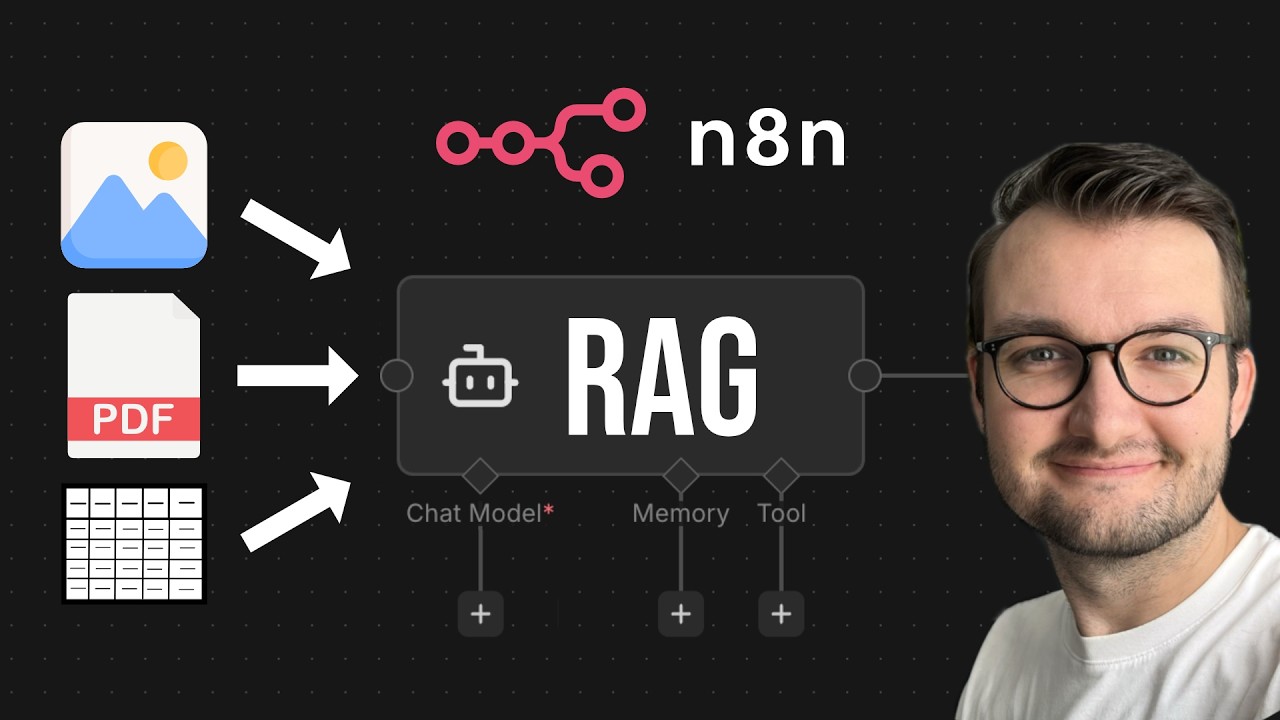
In diesem Video schauen wir uns an, wie man ein multimodales und hybrides RAG-System in n8n baut, das unterschiedliche Dokumenttypen in eine durchsuchbare Wissensdatenbank überführt. Das System kann nicht nur klassische Textdokumente verarbeiten, sondern auch gescannte PDFs, Bilder und strukturierte Daten in Form von Tabellen. Es entscheidet darüber hinaus selbst, welcher Zugriffstyp (z.B. semantische Suche oder SQL-Abfrage) für eine Anfrage am besten geeignet ist.
Um auch nicht maschinenlesbare Dokumente nutzbar zu machen, kommt Mistral OCR (Optical Character Recognition) zum Einsatz. Damit können Texte und Tabellen in einem LLM-freundlichen Format aus Scans extrahiert werden. Diese werden anschließend in einer Vektordatenbank gespeichert und stehen dort für semantische Suche zur Verfügung. So kann das System erklärende und kontextuelle Fragen auf Basis inhaltlicher Ähnlichkeit beantworten.
Zusätzlich lassen sich auch eingebundene Bilder mittels Mistral OCR extrahieren. Dadurch kann der RAG-Agent bei seinen Antworten nicht nur Text, sondern auch relevante Bilder direkt mit ausgeben.
Strukturierte Daten in Form von CSV-Dateien oder Google Sheets eignen sich dagegen nicht für eine Vektordatenbank. Durch das Aufteilen in Chunks gehen Zusammenhänge verloren, und Auswertungen wie Summen, Filter oder Vergleiche lassen sich so nicht zuverlässig durchführen. Solche Daten werden deshalb stattdessen in einer relationalen Datenbank gespeichert (Supabase / PostgreSQL).
Auf Basis der jeweiligen Anfrage entscheidet der RAG-Agent anschließend selbst, welche Retrieval-Strategie sinnvoll ist: Für erklärende oder kontextuelle Fragen nutzt er eine semantische Suche über eine Vektordatenbank, für Anfragen zu strukturierten Daten greift er auf SQL-Abfragen zurück, und wenn eine Anfrage eine vollständige Übersicht oder Zusammenfassung erfordert, lädt er den gesamten Inhalt eines Dokuments.
#rag #ragsystem #mistralocr #kichatbot
00:00 Intro
01:11 Demo
04:46 Architektur des RAG-Systems
06:49 Überblick & Datenbank Initialisierung (Supabase)
17:42 Google Drive Trigger
20:26 Daten aus Textdatei extrahieren
22:20 Daten aus PDF extrahieren (Mistral OCR)
38:23 Tabellarische Daten extrahieren
41:21 Daten in der Datenbank speichern
57:19 Daten löschen
1:00:03 Aufbau des RAG-Agents
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



















