BLIP: Начальная загрузка предварительной подготовки языка и изображения для унифицированного пони...
Автор: Yannic Kilcher
Загружено: 2022-03-23
Просмотров: 34954
#blip #review #ai
Кросс-модальное предобучение в последнее время стало очень популярным в глубоком обучении, особенно при совместном обучении моделей зрения и языка. Однако существует ряд проблем, таких как низкое качество наборов данных, ограничивающее производительность любой обученной на них модели, а также тот факт, что чисто контрастное предобучение сложно настроить для большинства последующих задач. BLIP объединяет различные задачи и цели в одном запуске предобучения и позволяет получить гораздо более универсальную модель, которую в статье сразу же используют для создания, фильтрации, очистки и, таким образом, самообучения собственного набора данных для ещё большего повышения производительности!
Спонсор: Zeta Alpha
https://zeta-alpha.com
Используйте код YANNIC, чтобы получить скидку 20%!
ПЛАН:
0:00 — Введение
0:50 — Спонсор: Zeta Alpha
3:40 — Обзор статьи
6:40 — Предварительное обучение Vision-Language
11:15 — Вклад в статью
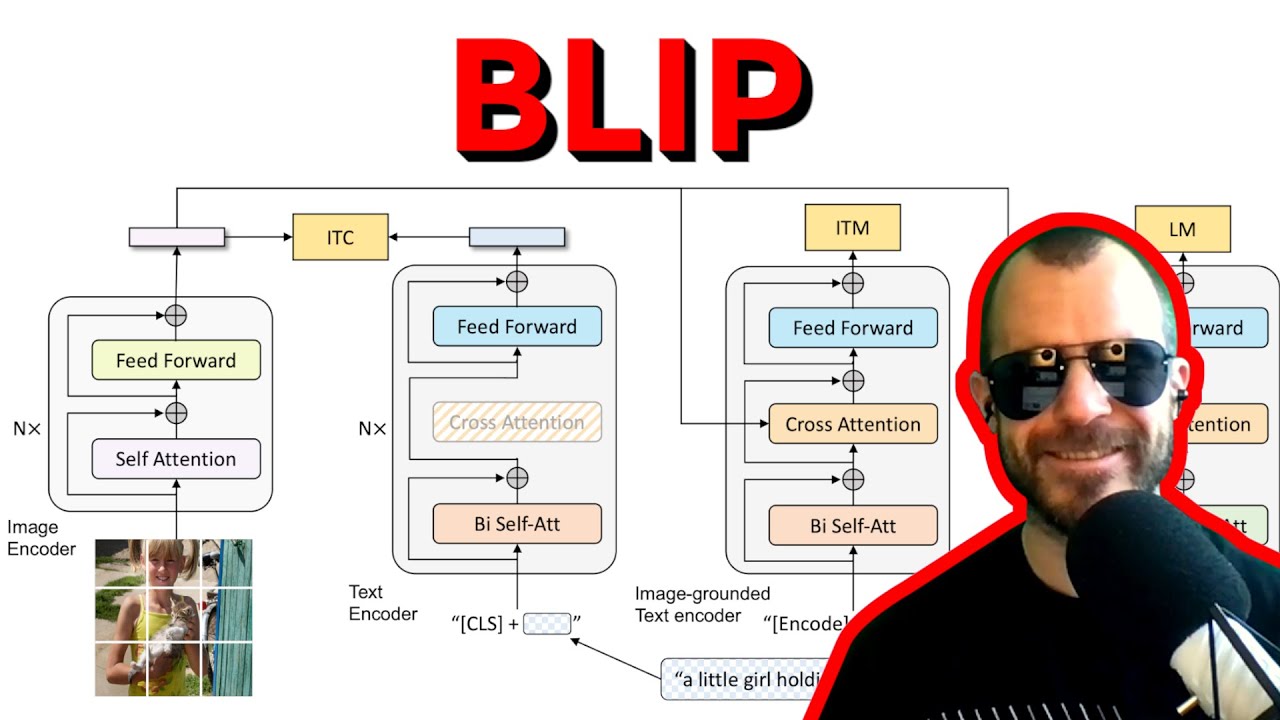
14:30 — Архитектура модели: множество частей для множества задач
19:50 — Как потоки данных в модели
26:50 — Совместное использование параметров между модулями
29:45 — Самонастройка субтитров и фильтрации
41:10 — Тонкая настройка модели для последующих задач
Статья: https://arxiv.org/abs/2201.12086
Код: https://github.com/salesforce/BLIP
Демонстрация: https://huggingface.co/spaces/Salesfo...
Аннотация:
Предварительное обучение Vision-Language (VLP) повысило производительность многих задач Vision-Language. Однако большинство существующих предобученных моделей демонстрируют отличные результаты только в задачах, основанных на понимании, или в задачах, основанных на генерации. Более того, повышение производительности было в значительной степени достигнуто за счет масштабирования набора данных с использованием зашумленных пар «изображение-текст», собранных из интернета, что является неоптимальным источником контроля. В данной статье мы предлагаем BLIP, новую платформу VLP, которая гибко переносится как на задачи понимания, так и на задачи генерации визуальных текстов. BLIP эффективно использует зашумленные веб-данные путем бутстрапа субтитров, где создатель субтитров генерирует синтетические субтитры, а фильтр удаляет зашумленные. Мы достигли передовых результатов в широком спектре задач, основанных на визуальном тексте, таких как поиск изображений и текста (+2,7% в средней отзывчивости при 1), создание субтитров к изображениям (+2,8% в CIDEr) и VQA (+1,6% в оценке VQA). BLIP также демонстрирует сильную способность к обобщению при прямом переносе на задачи, связанные с видеотекстом, с нуля. Код, модели и наборы данных доступны по этому https-адресу.
Авторы: Цзюньнань Ли, Дунсюй Ли, Цаймин Сюн, Стивен Хой
Ссылки:
Автодополнение кода TabNine (реферальная ссылка): http://bit.ly/tabnine-yannick
YouTube: / yannickilcher
Twitter: / ykilcher
Discord: / discord
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: / ykilcher
BiliBili: https://space.bilibili.com/2017636191
Если хотите поддержать меня, лучше всего поделиться контентом :)
Если хотите поддержать меня финансово (это совершенно необязательно и добровольно, но многие просили об этом):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: / yannickilcher
Биткойн (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Эфириум (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Лайткойн (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Монеро (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



![[Classic] Deep Residual Learning for Image Recognition (Paper Explained)](https://image.4k-video.ru/id-video/GWt6Fu05voI)
![Цепи Маркова — математика предсказаний [Veritasium]](https://image.4k-video.ru/id-video/QI7oUwNrQ34)














