23. Aula 23 - Clusterização no R
Автор: Professor Máiron Chaves
Загружено: 2025-01-29
Просмотров: 229
📊 Resumo do Vídeo: "Curso Ciência de Dados - Do Zero ao Iniciante (Aula 23: Clusterização no R)"
Nesta aula prática, StatiR apresenta como implementar clusterização no R, utilizando o algoritmo K-Means e abordando as etapas de preparação de dados, normalização e visualização dos clusters. A aula é voltada para a aplicação prática e interpretação dos resultados.
🛠️ 1. Configuração Inicial
Carregamento do Dataset:
O dataset utilizado contém dados de mamíferos e suas características, como percentual de água, proteína e lactose no leite.
A base é carregada e manipulada no R para remoção de colunas irrelevantes (ex.: nomes dos animais).
Normalização:
Por que não foi necessária?
Todas as variáveis estão em percentuais, já padronizadas.
Caso necessário:
O comando scale() pode ser usado para normalizar as variáveis com unidades diferentes.
📐 2. Cálculo da Distância
Distância Euclidiana:
Usada para medir a proximidade entre os pontos no dataset.
O comando dist() é utilizado para gerar a matriz de distâncias, que é a base para o algoritmo K-Means.
Exemplo:
Cada ponto (animal) é comparado com todos os outros para calcular as distâncias e determinar os grupos.
🌟 3. Implementação do K-Means
Definição de K:
O número de clusters é definido pelo usuário (ex.: K = 3).
Execução no R:
O comando kmeans() é usado para rodar o algoritmo.
Exemplo:
R
Copiar código
modelo = kmeans(dados, centers = 3)
O resultado inclui:
Centroides: Representam a média das variáveis em cada cluster.
Alocação: Atribuição de cada ponto ao seu cluster mais próximo.
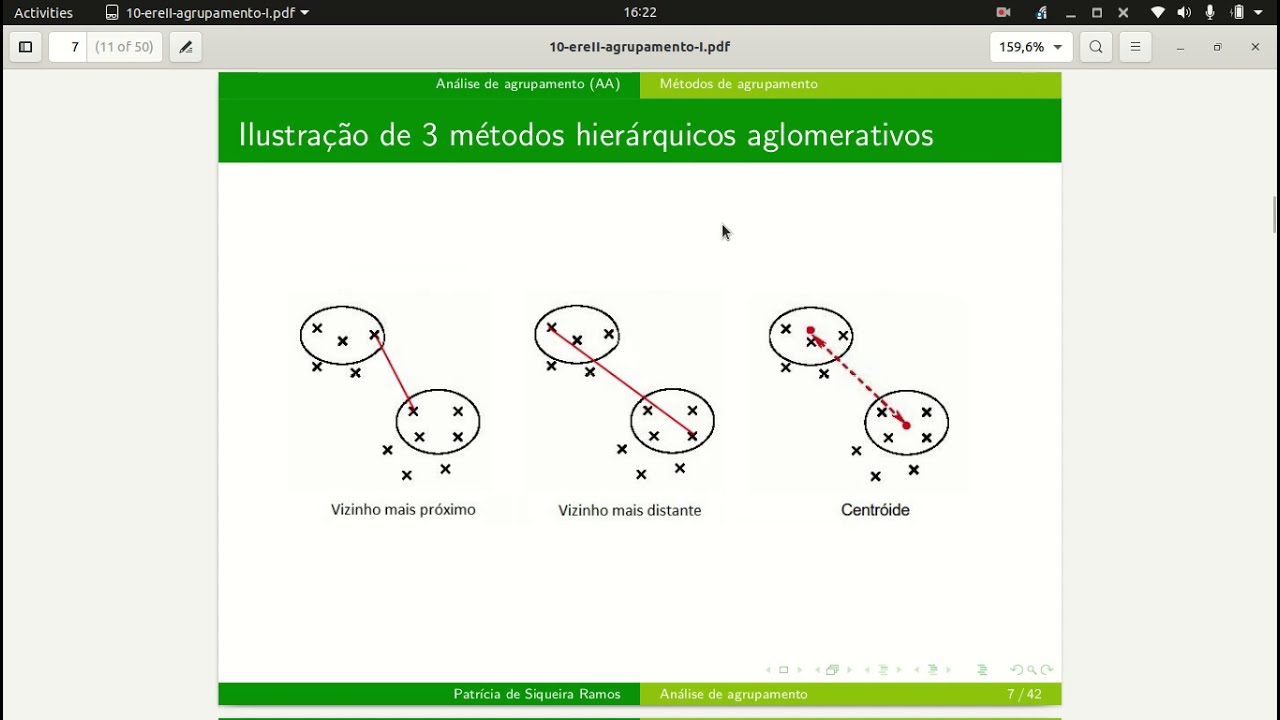
📈 4. Validação dos Clusters
Visualização com PCA:
Para facilitar a interpretação, o PCA é usado para reduzir a dimensionalidade dos dados.
Os clusters são plotados em duas dimensões, com cada cluster identificado por uma cor.
Interpretação Gráfica:
Se os pontos de um cluster estão bem separados dos outros, o modelo é considerado eficiente.
Medidas estatísticas, como o método do cotovelo, podem ser usadas para ajustar o número de clusters.
🚀 Aprofundando com Inspiração Prática
Desafie-se: Aplique o K-Means em um novo dataset e use o método do cotovelo para encontrar o número ideal de clusters.
PCA em Ação: Explore como diferentes combinações de variáveis afetam a separação dos clusters.
Impacto Real: Imagine como agrupar consumidores ou perfis de clientes pode ser aplicado em projetos reais de marketing ou recomendação.

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: