MicroFiche 1: A
Автор: tuned-org-uk
Загружено: 2025-12-03
Просмотров: 3
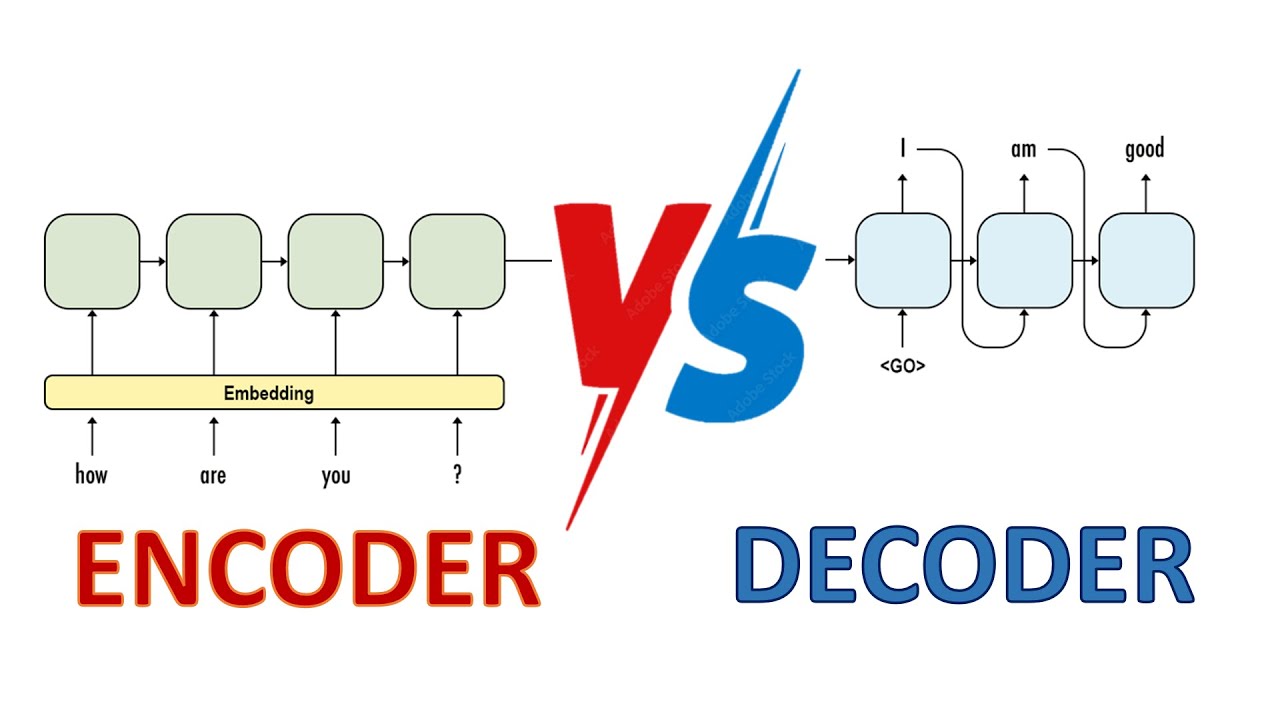
🏗️ Architecture Overview
This decoder-only transformer model processes input sequences and generates text one token at a time through a stack of identical decoder blocks. The implementation uses pre-norm residual connections, where normalization is applied before self-attention and feed-forward layers, then added back to the original input to prevent gradient explosion or vanishing during training.
⚡ Modern Components
Rotary Position Embeddings (RoPE)
Instead of traditional learned positional encodings, RoPE applies rotational transformations to query and key vectors in self-attention, enabling better generalization across different sequence lengths without adding learnable parameters.
Multi-Query Attention (MQA)
Reduces memory footprint by sharing key and value heads across multiple query heads, significantly decreasing KV cache size during inference while maintaining training performance. Key and value heads are repeated to match query heads before attention calculation.
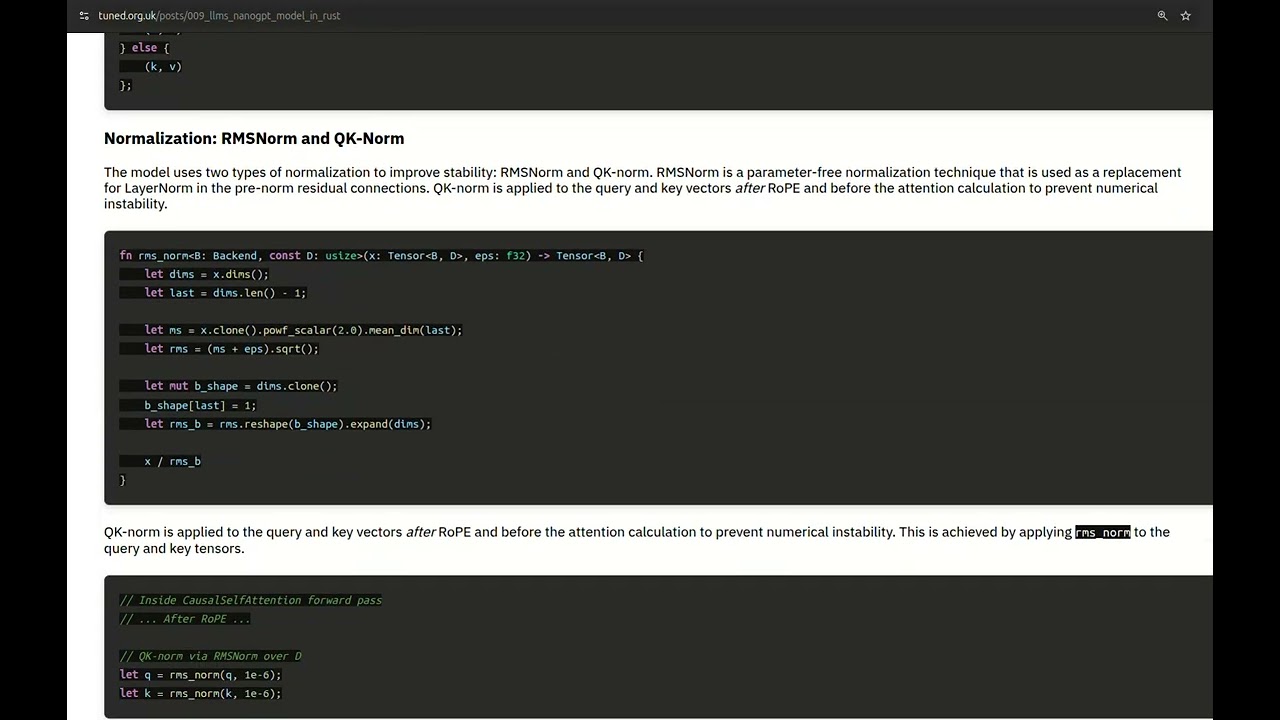
RMSNorm and QK-Norm
Two specialized normalization techniques improve stability: RMSNorm provides parameter-free normalization replacing LayerNorm in residual connections, while QK-norm is applied to query and key vectors after RoPE to prevent numerical instability.
Squared ReLU Activation
The feed-forward MLP uses squared ReLU activation (applying ReLU then squaring), which improves gradient flow especially on GPUs for better performance.
Logit Softcapping
A tanh-based "softcap" bounds output logit values to maintain stable softmax behavior during text generation, preventing extreme values.
🦀 Why Rust + Burn.dev?
Burn.dev is both a tensor library and deep learning framework optimized for numerical computing, model inference, and training. It leverages Rust's type system to perform optimizations normally only available in static-graph frameworks, delivering optimal speed without sacrificing flexibility.
Multi-Platform Support:
GPU Backends: CUDA (Nvidia), ROCm (AMD), Metal (Apple), Vulkan (Intel, Qualcomm, others), WebGPU, Candle, LibTorch
CPU Backends: CubeCL, NdArray, Candle, LibTorch
Special Platforms: WebAssembly support, no-std environments
Burn enables training in the cloud and deploying on diverse customer hardware—from desktop GPUs to edge devices—all with robust implementations.
🎯 Key Takeaways
This implementation demonstrates the Rust ecosystem's readiness for LLM development, with burn.dev approaching high standards of usability and performance. The combination of modern transformer optimizations (RoPE, MQA, specialized normalization) with Rust's safety guarantees creates an efficient, high-quality text generation foundation.
The future looks promising for large-scale production installations based on Rust's numerical stack (ndalgebra, ndarray) and emerging deep learning frameworks.
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: