Why decentralized, open-source training will win — Justus Mattern, Prime Intellect
Автор: DEMi network
Загружено: 2025-09-11
Просмотров: 487
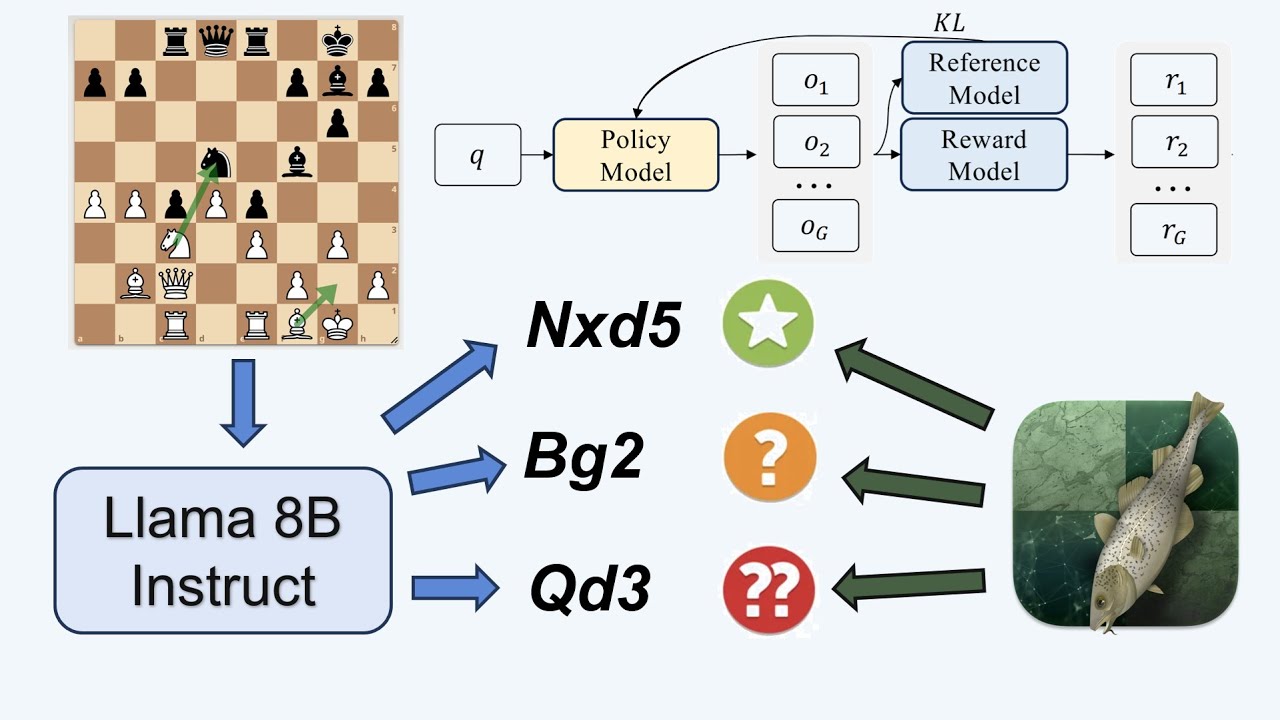
Prime Intellect created the first reasoning model, INTELLECT 2, with decentralized RL training run using idle GPUs contributed by their community. 75% of training compute was inference time.
They’re building more conviction on open-source, decentralized RL as a path to AGI:
1. With RL, LLMs iteratively generates its own training data. Since inference is parallelizable; each GPU can host a model replica and sample independently.
2. The bottleneck in RL is the availability of RL environments — reward functions and tool access during inference rollouts. Specialized environments are necessary to train models for tasks such as writing fast CUDA kernels, analyzing scientific datasets, or searching the web. PI launched an open-source RL environment development, Environments Hub, to address this.
In his talk at DEMi 3 Summit, Justus Mattern, Research Engineer at PrimeIntellect, shows how they're scaling RL to open AGI.
If you’re excited to help shape the future of a sovereign open-source AI ecosystem, contribute to the Environments Hub or join PI’s research team!

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: