Выжимаем максимум из Qwen3-4B с помощью llama.cpp на ноутбуке с Ryzen 7 5800H и GTX 1650 (часть 2)
Автор: Нейросети | ilovedocs
Загружено: 2025-09-24
Просмотров: 67
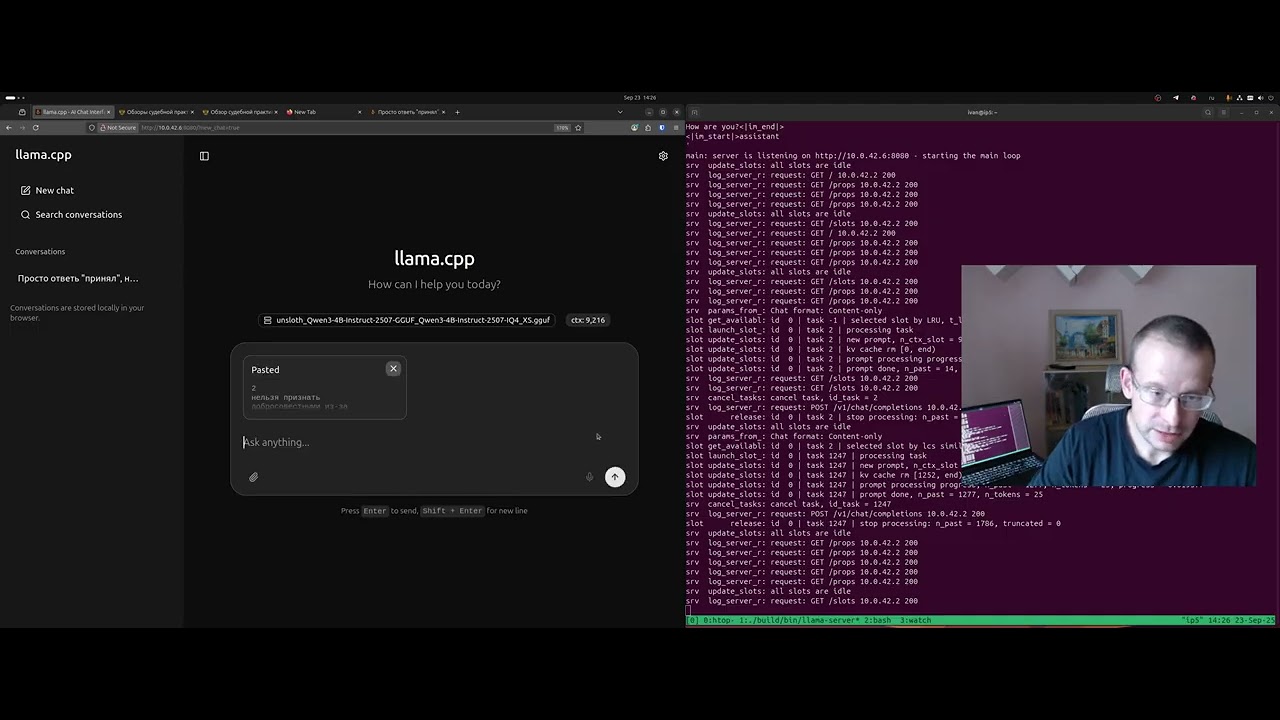
Активист Иван Толстошеев специально для ilovedocs снял видео о том, как установить и использовать китайскую модель qwen3-4b на личном или рабочем ноутбуке (всего лишь 4GB видеопамяти). На этом видео выжимает максимум из Qwen3-4B с помощью llama.cpp на ноутбуке с Ryzen 7 5800H и GTX 1650. Цель - проверить предел возможностей обычного "железа".
Локальные модели нужны для обработки данных, которые вы не готовы предоставлять публичным моделям. Иван показывает, что они могут работать в домашних условиях и быть достаточно эффективными.
Результаты теста:
Скорость генерации: ~40 токенов/сек
Контекстное окно: до 10 000 токенов (~8-10 страниц текста)
Обработка промпта (7000 токенов): ~300-400 токенов/сек
Решение практической задачи: успешное извлечение фактов и обобщение информации из документа
Вывод: 4GB видеопамяти достаточно для решения практических задач по анализу текста.
Соцсети ilovedocs:
https://t.me/ilovedocs
https://t.me/docsllm
Канал Ивана:
https://t.me/nearlytheru
В канале и чате - тысячи единомышленников, нейросетевой журнал, подборки промптов, онбординг-FAQ, трансляции, много общения и опыта.
#ChatGPT #юристы
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



















