Bài 10 Big Data. Phân tích Dữ liệu lớn
Автор: Albaz
Загружено: 2026-01-15
Просмотров: 2
** Lưu ý: Tài liệu này được biên soạn bằng NotebookLM
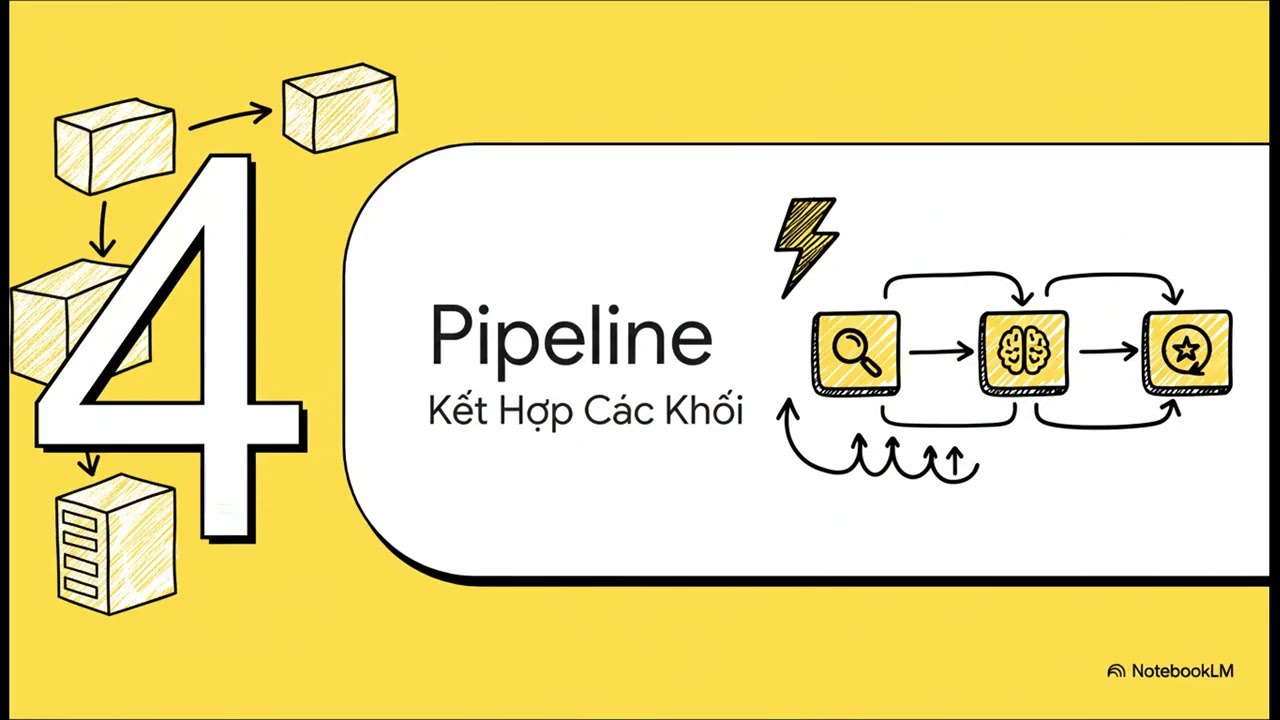
Tài liệu này cung cấp cái nhìn tổng quan về thư viện học máy (MLlib) thuộc hệ sinh thái Apache Spark dùng trong phân tích dữ liệu lớn. Nội dung tập trung giải thích các thành phần cốt lõi bao gồm Transformer, công cụ giúp chuyển đổi dữ liệu, và Estimator, thuật toán được huấn luyện để tạo ra mô hình. Nguồn thông tin cũng trình bày khái niệm Pipeline, một chuỗi các giai đoạn xử lý giúp tự động hóa quy trình làm việc từ dữ liệu thô đến khi dự báo. Ngoài ra, văn bản còn liệt kê các tính năng quan trọng như phân loại, hồi quy và các công cụ xử lý đặc trưng dữ liệu. Đây là bài giảng từ Trường Công nghệ Thông tin và Truyền thông thuộc Đại học Bách Khoa Hà Nội nhân kỷ niệm 25 năm thành lập. Các ví dụ minh họa cụ thể như Logistic Regression và Tokenizer giúp làm rõ cách thức vận hành của hệ thống trong thực tế.
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



















