Transformers architecture mastery | Full 7 hour compilation
Автор: Vizuara
Загружено: 2025-11-28
Просмотров: 7712
Join Vision Transformer PRO
– Access to all lecture videos– Hand-written notes– Private GitHub repo– Private Discord– “Transformers for Vision” book by Team Vizuara (PDF)– Email support– Hands-on assignments– Certificate
https://vizuara.ai/courses/transforme...
--------
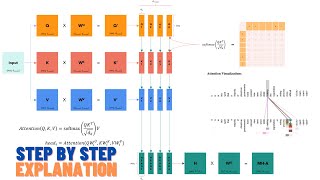
Transformers Explained: The Complete 7-Hour Deep Dive into the Architecture that Changed AI
This 7-hour marathon lecture is the ultimate resource to understand the transformer architecture from the ground up. Whether you are a researcher, engineer, or student, this compilation takes you through every component that makes transformers the foundation of modern AI models used in vision, language, and multimodal tasks.
We start from the very beginning - the motivation behind replacing recurrent models, the intuition behind self-attention, and the mathematical derivation of each module. From there, we move into the detailed structure of the encoder-decoder architecture, the multi-head attention mechanism, positional encoding, feed-forward layers, and layer normalization. Every theoretical concept is supported by practical coding examples so you can see exactly how it works in implementation.
As the lecture progresses, you will build and understand key components such as:
Scaled Dot-Product Attention
Multi-Head Attention and Residual Connections
Encoder and Decoder Blocks
Tokenization, Embedding Layers, and Positional Encodings
Masked Attention for Language Modeling
The Training Objective of Transformers
You will also see how these foundational ideas evolved into today’s most powerful models like BERT, GPT, Vision Transformers (ViT), and CLIP, bridging the gap between NLP, vision, and multimodal AI.
By the end of this 7-hour session, you will have a complete, working mental model of the transformer architecture and its variants, ready to apply it in your own research or projects.
What you will learn:
The motivation, design, and inner workings of transformers
How self-attention replaces recurrence
How information flows through the encoder and decoder
How transformers are trained and scaled
How the same architecture powers models across NLP and Vision
Ideal for:
Learners who want to deeply understand the transformer architecture, its mathematics, its implementation, and how it serves as the backbone for modern AI systems.
Part of:
📘 Transformers for Vision Series by Vizuara
If you have ever wanted to truly master the transformer model that powers ChatGPT, BERT, ViT, and CLIP - this lecture is your complete guide.

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: