Tutorial 2: Extracting Information from Documents
Автор: NLP and CSS 201: Beyond the Basics
Загружено: 2021-10-27
Просмотров: 50657
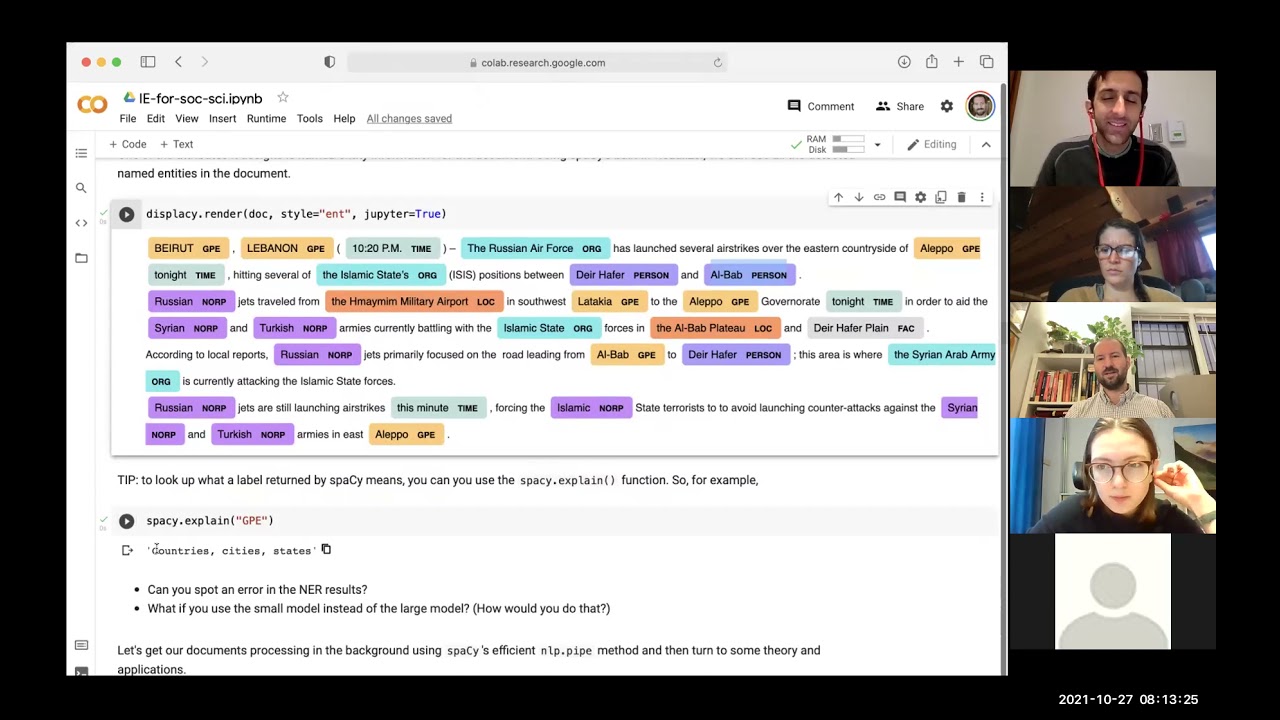
Tutorial description: This workshop provides an introduction to information extraction for social science–techniques for identifying specific words, phrases, or pieces of information contained within documents. It focuses on two common techniques, named entity recognition and dependency parses, and shows how they can provide useful descriptive data about the civil war in Syria. The workshop uses the Python library spaCy, but no previous experience is needed beyond familiarity with Python.
Tutorial host: Andrew Halterman
Colab notebook (accompanying code and slides):
https://colab.research.google.com/dri...
This is part of a larger tutorial series, NLP+CSS 201: Beyond the basics, which is organized by Ian Stewart and Katherine Keith. Website: https://nlp-css-201-tutorials.github....
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: