How DeepSeek made Transformers 95% more efficient
Автор: Prompt Engineering
Загружено: 2026-01-19
Просмотров: 597
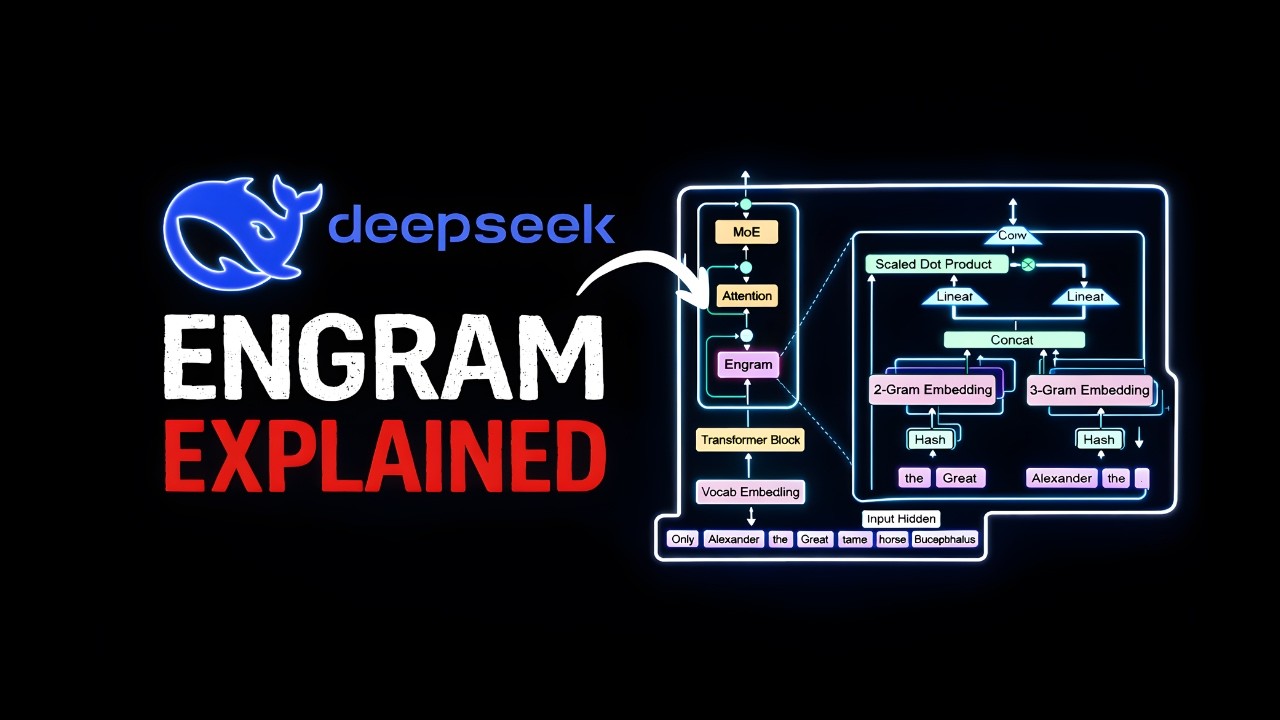
In this video, I delve into a groundbreaking paper by DeepSeek called Engram that addresses the inefficiencies of transformer-based large language models (LLMs). Traditional LLMs use deep computation for both complex reasoning and simple recall, leading to wasted computational resources. Engram introduces a conditional memory mechanism that uses scalable lookup tables, effectively distinguishing between tasks that need deep computation and those that require simple memory recall. This approach has shown significant improvements in both knowledge and reasoning tasks, optimizing the efficiency and performance of LLMs. I also discuss the hardware implications and potential limitations of this new method.
LINKS:
https://github.com/deepseek-ai/Engram...
https://github.com/deepseek-ai/Engram...
My voice to text App: whryte.com
Website: https://engineerprompt.ai/
RAG Beyond Basics Course:
https://prompt-s-site.thinkific.com/c...
Signup for Newsletter, localgpt:
https://tally.so/r/3y9bb0
Let's Connect:
🦾 Discord: / discord
☕ Buy me a Coffee: https://ko-fi.com/promptengineering
|🔴 Patreon: / promptengineering
💼Consulting: https://calendly.com/engineerprompt/c...
📧 Business Contact: engineerprompt@gmail.com
Become Member: http://tinyurl.com/y5h28s6h
💻 Pre-configured localGPT VM: https://bit.ly/localGPT (use Code: PromptEngineering for 50% off).
Signup for Newsletter, localgpt:
https://tally.so/r/3y9bb0
00:00 Memory problem with LLMs
00:25 Complex Reasoning vs. Simple Recall
00:56 The Inefficiency of Transformer-Based Architectures
01:22 DeepSeek's Engram: A New Approach
04:36 How Engram Works
07:30 Performance and Limitations of Engram
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:



















