Transformer Architecture Explained
Автор: Under The Hood
Загружено: 2025-11-17
Просмотров: 6803
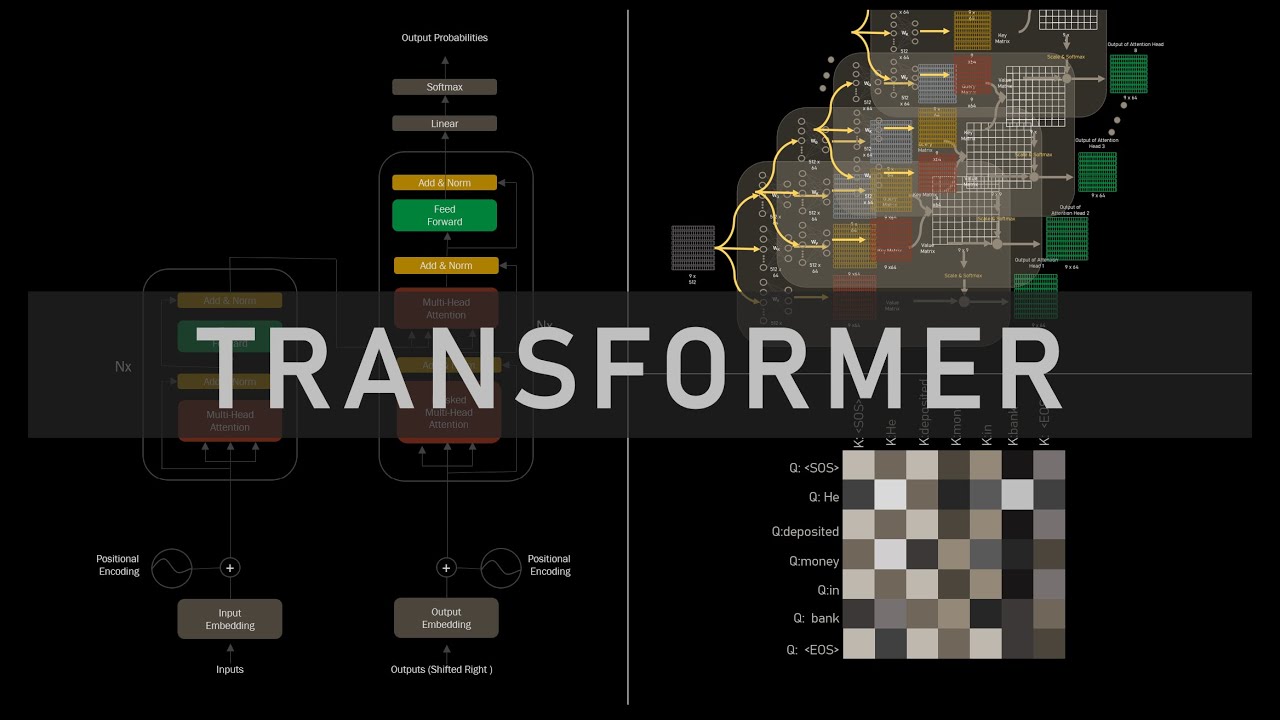
Transformer Architecture Explanation from the paper: Attention is all you need.
Watch each components of Transformer Architecture in Detail:
1) Tokenization
• LLM Training Starts Here: Dataset Preparat...
2) Embeddings
• What Are Word Embeddings?
3) Attention Mechanism
• How Attention Mechanism Works in Transform...
Read Original Paper Here:
https://arxiv.org/abs/1706.03762
Timestamp:
0:00 - Introduction
1:15 - Dataset Preparation
2:15 - Encoder: Tokenization, Embedding, PE
5:50 - Encoder: Attention Mechanism
10:05 - Encoder: MHA, Add & Norm, FFNN
13:20 - Decoder: Tokenization, Embedding, PE, MMHA
16:27 - Decoder: Cross Attention, Output
18:05 - Transformer Inference
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:

![Как происходит модернизация остаточных соединений [mHC]](https://image.4k-video.ru/id-video/jYn_1PpRzxI)
![How AI Taught Itself to See [DINOv3]](https://image.4k-video.ru/id-video/oGTasd3cliM)




![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://image.4k-video.ru/id-video/Y-o545eYjXM)

![How DeepSeek Rewrote the Transformer [MLA]](https://image.4k-video.ru/id-video/0VLAoVGf_74)




![He Co-Invented the Transformer. Now: Continuous Thought Machines [Llion Jones / Luke Darlow]](https://image.4k-video.ru/id-video/DtePicx_kFY)




