Предварительная подготовка больших языковых моделей: все, что вам нужно знать!
Автор: Under The Hood
Загружено: 2025-03-17
Просмотров: 10433
#llm #gpt #встраивание #машинное обучение #ai
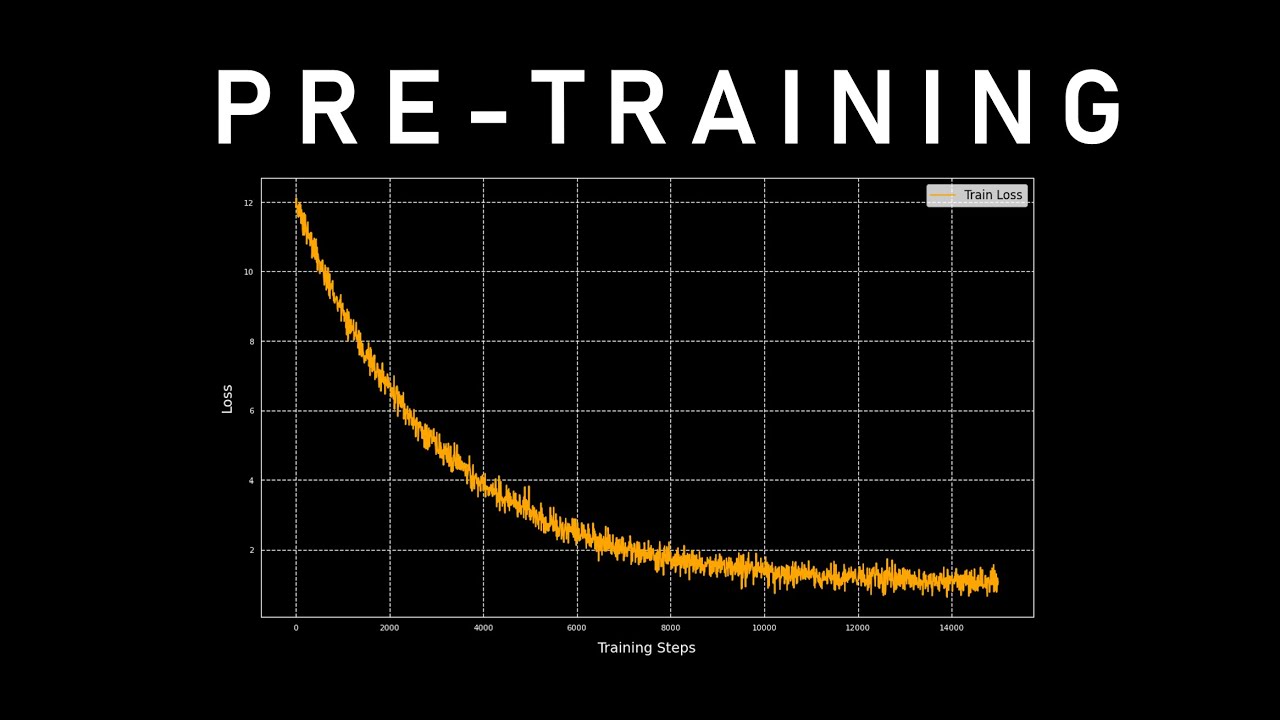
Обучение большой языковой модели — сложный процесс, включающий обучение модели пониманию и генерации текста, похожего на человеческий. Это достигается путем предоставления ей огромных объемов текстовых данных, что позволяет ей изучать закономерности, контекст и взаимосвязи между словами. Процесс обучения требует значительных вычислительных мощностей и часто опирается на специализированное оборудование, такое как графические процессоры и тензорные процессоры, для обработки миллиардов параметров. Кроме того, методы оптимизации и параллельная обработка играют решающую роль в обеспечении эффективности и масштабируемости обучения.
В этом видео я объясняю процесс предварительной подготовки больших языковых моделей, разбирая ключевые компоненты, которые делают их мощными и эффективными. Я освещаю такие важные темы, как роль больших наборов данных, требуемые вычислительные ресурсы и различные оптимизации, повышающие производительность, а также некоторые важные гиперпараметры, которые следует учитывать.
Временные метки:
0:00 — Введение
0:40 — Архитектура модели
2:35 — Набор данных
4:38 — Вычисления
6:30 — Параллелизм на GPU
8:56 — Прямое распространение
10:16 — Функция потерь кросс-энтропии
13:18 — Оптимизация
16:05 — Гиперпараметры
17:50 — Обучение
18:30 — Вывод
20:43 — Тонкая настройка
21:45 — Заключение
Ресурсы:
Pytorch FSDP: https://arxiv.org/abs/2304.11277
ZeRO: https://arxiv.org/abs/1910.02054
Megatron: https://arxiv.org/abs/1909.08053
Музыка: Винсент Рубинетти
Скачать музыку можно здесь Bandcamp:
https://vincerubinetti.bandcamp.com
Слушайте музыку на Spotify:
https://open.spotify.com/artist/2SRhE...
Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:
![Как происходит модернизация остаточных соединений [mHC]](https://image.4k-video.ru/id-video/jYn_1PpRzxI)
![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://image.4k-video.ru/id-video/Y-o545eYjXM)








![Why Deep Learning Works Unreasonably Well [How Models Learn Part 3]](https://image.4k-video.ru/id-video/qx7hirqgfuU)




![The F=ma of Artificial Intelligence [Backpropagation, How Models Learn Part 2]](https://image.4k-video.ru/id-video/VkHfRKewkWw)



