RL 6: Policy iteration and value iteration - Reinforcement learning
Автор: AI Insights - Rituraj Kaushik
Загружено: 2019-02-18
Просмотров: 58444
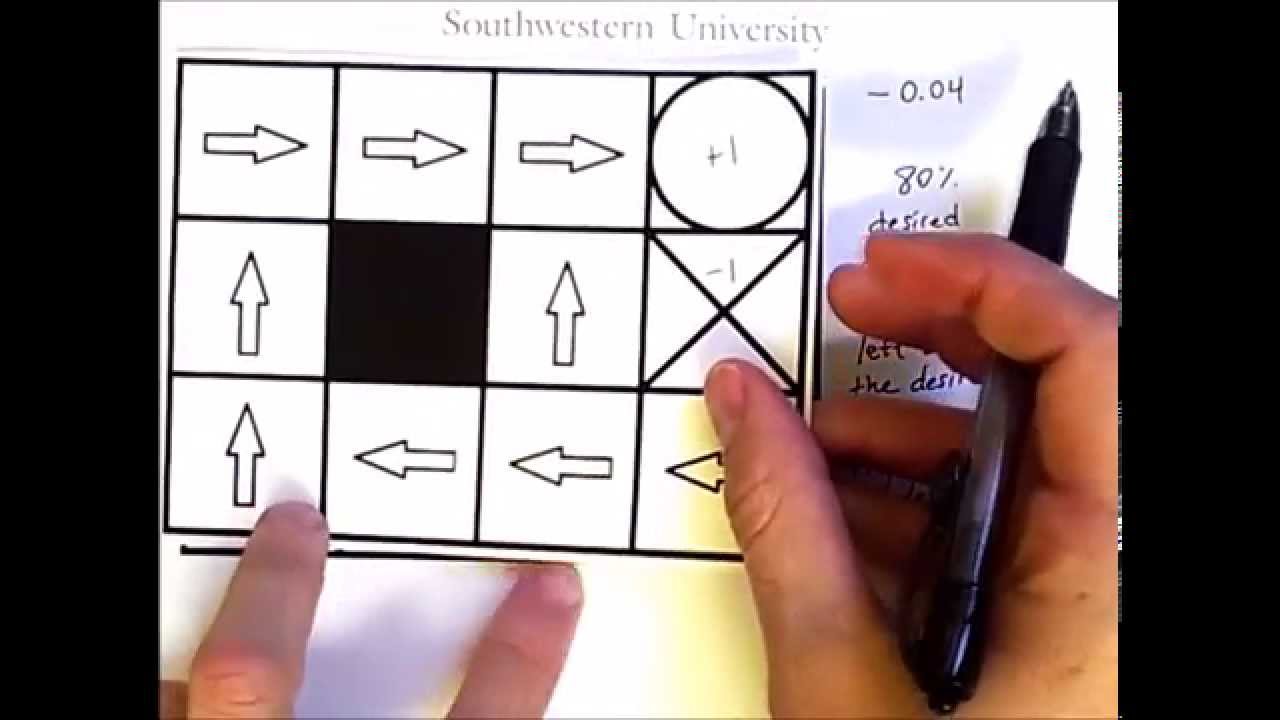
Policy iteration and value iteration - Policy iteration and value iterations are two very interesting as well as important algorithms in Reinforcement learning.These two algorithms are based on dynamic programming and Bellman equation. Value iteration algorithm and policy iteration algorithm are very useful for finding the optimal policy when the agent knows sufficient details about the environment model. In this video we alo talkabout Bellman optimality equation and optimal value function in reinforcement learning.
Reinforcement learning tutorial series:
1. Multi-armed Bandits: • RL 1: Multi-armed Bandits 1
2. Multi-Armed Bandits - Action value estimation: • RL 2: Multi-Armed Bandits 2 - Action value...
3. Upper confidence bound: • RL 3: Upper confidence bound (UCB) to solv...
4. Thompson Sampling: • RL 4: Thompson Sampling - Multi-armed bandits
5. Markov Decision Process - MDP: • RL 5: Markov Decision Process - MDP | Rein...
6. Policy iteration and value iteration: • RL 6: Policy iteration and value iteration...

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке: