MÉTRIQUES de RÉGRESSIONS en DATA SCIENCE (Coefficient de Détermination, Erreur Quadratique, etc... )
Автор: Machine Learnia
Загружено: 2019-12-09
Просмотров: 91238
Ce tutoriel français Machine Learning / Data Science explique en détail l'origine de l'erreur quadratique moyenne, de l'erreur absolue moyenne, et du coefficient de détermination R2.
En Data Science et en statistiques, ces métriques sont utilisées pour évaluer la qualité d'un estimateurs de régression.
Tout commence par le calcul de l'erreur résiduelle, définie par la différence entre les prédictions de l'estimateurs (y_pred) et les valeurs attendues (y_vrai)
L'erreur absolue moyenne calcule ainsi la valeur absolue de ces erreurs, pour en faire la moyenne. En anglais, on l'appelle "Mean Absolute Error" (MAE)
De son coté, l'erreur quadratique moyenne calcule le carré des erreurs résiduelles, pour en faire la moyenne. En anglais, on l'appelle "Mean Squared Error" (MSE)
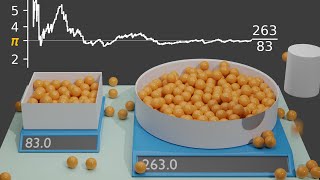
Ainsi, si un estimateur de distance de freinage effectue 2 prédictions qui donnent lieu a une erreur de 4 metres, et une erreur de 0 metre, la MAE calcule une erreur moyenne de 2 metres (ce qui est logique), tandis que la RMSE calcule une erreur moyenne de 2.8 metres (ce qui peut sembler étrange)
Ce qui explique cette différence, c'est que la MSE accorde une importance exponentielle aux erreurs d'un estimateur.
Ainsi, il est conseillé d'utiliser la MAE (erreur absolue moyenne) pour obtenir une moyenne représentative des erreurs de votre estimateur.
En revanche, il est conseillé d'utiliser la MSE (erreur quadratique moyenne) quand vous voulez sélectionner un parmi plusieurs estimateurs, retenant l'estimateurs qui ne fait pas "trop" de grandes erreurs.
D'une maniere générale, il est conseillé d'utiliser plusieurs métriques pour évaluer un estimateur, vous récoltez ainsi plus d'information sur vos erreurs :
Calculer l'erreur moyenne, la médiane, les quantiles, et pourquoi pas l'histogramme de vos erreurs afin de déterminer la loi de distribution suivie.
Le coefficient de Determination R2 est très connu, et implémenté de base dans la méthode score des estimateurs de régression. Il mesure le rapport des erreurs quadratiques avec la variance des données.
Si par exemple, un modèle effectue des erreurs de l'ordre de 1000 euros pour prédire un prix d'appartement, mais que les prix du marché varient eux-mêmes de plus de 100,000 euros, alors il existe un rapport de 0.01. Le coefficient de détermination est donc R2 = 0.99
Strings pour les metrics :
https://scikit-learn.org/stable/modul...
► Merci de me soutenir sur Tipeee (et recevez des bonus !)
https://fr.tipeee.com/machine-learnia
► MON SITE INTERNET EN COMPLÉMENT DE CETTE VIDÉO:
https://machinelearnia.com/
► REJOINS NOTRE COMMUNAUTÉ DISCORD
/ discord
► Recevez gratuitement mon Livre:
APPRENDRE LE MACHINE LEARNING EN UNE SEMAINE
CLIQUEZ ICI:
https://machinelearnia.com/apprendre-...
► Télécharger gratuitement mes codes sur github:
https://github.com/MachineLearnia
► Abonnez-vous : / @machinelearnia
► Pour En Savoir plus : Visitez Machine Learnia : https://machinelearnia.com/
► Qui suis-je ?
Je m’appelle Guillaume Saint-Cirgue et je suis Data Scientist au Royaume Uni. Après avoir suivi un parcours classique maths sup maths spé et avoir intégré une bonne école d’ingénieur, je me suis tourné vers l’intelligence artificielle de ma propre initiative et j’ai commencé à apprendre tout seul le machine learning et le deep learning en suivant des formations payantes, en lisant des articles scientifiques, en suivant les cours du MIT et de Stanford et en passant des week end entier à développer mes propres codes.
Aujourd’hui, je veux vous offrir ce que j’ai appris gratuitement car le monde a urgemment besoin de se former en Intelligence Artificielle.
Que vous souhaitiez changer de vie, de carrière, ou bien développer vos compétences à résoudre des problèmes, ma chaîne vous y aidera.
C’est votre tour de passer à l’action !
► Une question ? Contactez-moi: [email protected]

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:






![[ML] Fonctions de perte - Erreur Quadratique Moyenne (L2Loss, MSE)](https://ricktube.ru/thumbnail/sBdAU6sLpfM/mqdefault.jpg)