Deep-Learning: How to improve the Scalability of The Transformer Architecture Part-1
Автор: AI Super Storm
Загружено: 2022-03-12
Просмотров: 427
Part-1 Contains.
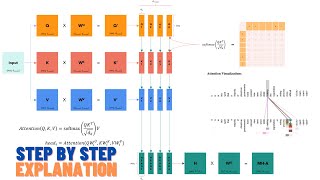
1. Paper: “Transformer Quality in Linear Time”
2. Gated Linear Unit
3. Gated Attention Unit
4. Mixed Chunk Attention
5. Relative Position Bias
6. Squared RELU
Link for the supporting videos.
1. Multi-Head Self Attention and Traditional Transformer architecture: • Transformer to RNN (T2RNN) Part-1
2. XLNet Architecture:
-Part-1: • XLNet Made Easy Part-1
-Part-2: • XLNet Made Easy PART 2
-Part-3: • XLNet Made Easy PART 3
3. Transformer-to-RNN (T2RNN):
-Part-1: • Transformer to RNN (T2RNN) Part-1
-Part-2: • Transformer to RNN (T2RNN) Part-2
Reference
[1]. Hua, Weizhe, Zihang Dai, Hanxiao Liu, and Quoc V. Le. "Transformer Quality in Linear Time." arXiv preprint arXiv:2202.10447 (2022).
[2] Shazeer, Noam. "Glu variants improve transformer." arXiv preprint arXiv:2002.05202 (2020)
[3]Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. "Attention is all you need." Advances in neural information processing systems 30 (2017).

Доступные форматы для скачивания:
Скачать видео mp4
-
Информация по загрузке:

















![Физически-информированные нейронные сети (PINN) [Машинное обучение с учетом физики]](https://ricktube.ru/thumbnail/-zrY7P2dVC4/mqdefault.jpg)
